
文|摩登AI 三石
編輯 | 聶風
大模型已成兵家必爭之地。
訓練模型,最關鍵的環節之一是投喂數據。
那么訓練AI的數據由誰提供,AI成長的養分,又從何而來?
在東西競跑之下,迭代大模型是核心根本,而標注中文數據,同等重要。
01、海量數據投喂出的AI
使用英文和其他語言的ChatGPT時,體驗有差別嗎?
有,ChatGPT英文確實比其他語言表現更好。
這種差異除了ChatGPT英文在使用過程中受到的訓練更多,同時也要歸功于模型創建時期的資料投喂。
2020年,OpenAI在投喂海量數據、更接近人腦的超大基礎模型GPT-3模型上持續提升,終于在2022年11月,ChatGPT誕生。
ChatGPT足夠智能,是因為它的核心任務是將一個文本進行合理性延續,即根據已有的文本,生成一個符合上下文背景和書寫習慣的合理內容。
因此,前期的海量資料投喂與模型訓練才是其后期使用過程中最大的差異原因。
據悉,ChatGPT的大模型數據主要來自以下幾方面:
維基百科:ChatGPT使用了英文版維基百科的數據,包含了超過640萬篇文章,超過40億個詞。
書籍:ChatGPT使用了ProjectGutenberg和BookCorpus的數據,包含了超過10萬本書籍,超過20億個詞。
期刊:ChatGPT使用了PubMedCentral和arXiv的數據,包含了超過100萬篇期刊文章,超過10億個詞。
Reddit鏈接:社交媒體網站Reddit上的各種帖子和評論,包含了用戶之間的對話和互動。ChatGPT使用了Reddit的數據,包含了超過18億條鏈接和評論,超過100億個詞。
CommonCrawl:包含超過31億個網頁內容,超過4100億個詞。
其他數據集:ChatGPT使用了GitHub的代碼倉庫、WebText2的新聞文章、OpenSubtitles的電影字幕等數據。
從ChatGPT資源投喂上可以看出,ChatGPT獲得了更多的英文數據,大模型訓練時,也更多地使用英文,而非中文。
所以,在現實使用過程中,ChatGPT英文將比中文反應更快,更智能。反過來,中國大廠創建的人工智能大模型,中文版應比英文版反應更快,更智能。
據悉,目前中國大廠創建的人工智能大模型,數據投喂資源主要分為三類:
公開數據集,如中文維基百科、中文新聞語料庫、中文問答語料庫等;自有數據集,這些數據集是由各個大廠自行收集、整理、標注的,包括用戶行為數據、搜索引擎數據、社交媒體數據、電商平臺數據等;合作數據集,這些數據集是由各個大廠與其他機構或組織合作獲取的,包括政府部門數據、行業協會數據、科研機構數據等。
一個人工智能大模型的創建,不僅需要超高的運算能力,也需要海量數據投喂和大量的數據標注員。
02、賽博流水線上的民工
人工智能為什么需要數據標注員?
在人工智能大模型投入海量的數據后,還需要像人一樣,辨別、理解這些數據,才能成長,成熟,而這個過程離不開數據標注員。
對于人工智能而言,有標簽的數據才是有用的數據。

例如人臉識別,人工智能本身不會識別物體,只有當人臉關鍵點被一一標注之后,計算機才能建立起對人臉的認知。
對數據進行標注是人工智能的一個必須過程。
可以說,數據標注員就是人工智能的老師,幫助人工智能成長。那么,數據標注員每天都如何調校人工智能呢?
數據標注員身上的標簽是“互聯網民工”、“賽博流水線”。他們每天的日常工作,就是坐在一間如同初代網吧的屋子里,每天對著電腦劃拉鼠標幾千次。不停地對海量數據進行清洗、分類、畫框、注釋、標記等操作。
他們將大量的文字、語音、圖像打上標記,例如“眼珠”、“四川話”、“綠化帶”等。只有被標注過的數據,才能被人工智能模型識別,訓練出它的分辨能力。
例如標記道路圖片,標注道路圖片上的物體名稱、顏色等信息。業內人士稱這種工作位“拉框”。

他們或許并不明白“什么是人工智能”,但卻實實在在是人工智能的老師。
2021年版的《人工智能訓練師國家職業技能標準》中,對該職業的能力特征描述是“具有一定的學習能力、表達能力、計算能力;空間感、色覺正常”,普遍受教育程度寫的是“初中畢業”。
這意味著,標注員是一份幾乎沒有門檻的職業。
美國《時代》雜志曾發表過一份調查,OpenAI為訓練ChatGPT使用了非洲肯尼亞外包勞工。
據悉,肯尼亞首都內羅畢有30多名ChatGPT的數據標注員,他們每天工作9個小時,閱讀150-200段文字。
標注員需要從這些文字中標注出包含性、暴力與仇恨言論的內容,由于每天閱讀大量極具沖擊力的文字,有人會連續做噩夢。
欠發達地區的標注員不在少數。肯尼亞、烏干達和印度,有不少人是谷歌、Meta和微軟等硅谷企業的數據標注員。
這些數據標注員的實得工資約為每小時1.32美元至2美元。這在當地已經算得上中產收入,所以數據標注員雖然會因工作而做噩夢,但他們并沒有討厭這份工作。
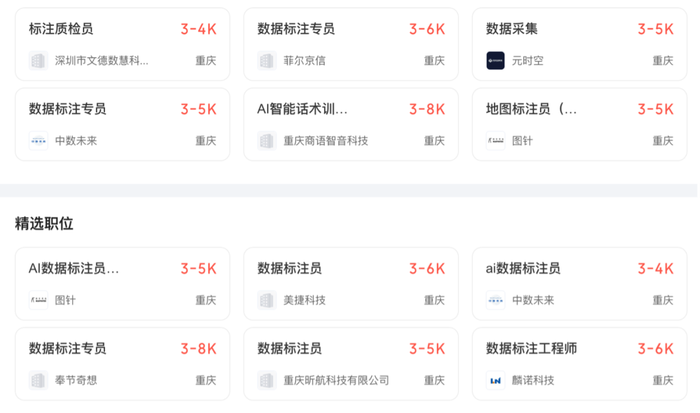
而在BOSS直聘等招聘網站上,數字標注員的公司月工資大都在3K-5K,崗位要求在大專及以上學歷,專業不限。在貴州、西安等地的縣城里,數據標注員的工資僅僅過千。
人工智能快速成長的背后,數據標注員像一群卑微的工蟻,默默地搬運著過冬的食物。
03、即將被取代的老師
中國的數據標注公司主要分為兩類,一是人工智能公司內部的標注公司,二是商務流程外包公司。
大廠內部標注公司有京東的京東眾智,百度的百度眾測,網易的網易有數,阿里的阿里數據標注、騰訊的騰訊數據標注,這些大廠都已經擁有自己的標注平臺和工具。
其他新興的國內數據標注公司,有龍貓數據、Testin云測、倍賽BasicFinder、數據堂等,這些公司都具有相當的規模。
截至2021年初,數據標注企業分布的top5城市是:北京185家,上海84家,成都68家,深圳63家,杭州46家。
這5個城市都是人工智能技術發展和應用的重要區域,擁有大量的需求方和合作伙伴,同時擁有較為完善的政策支持和產業環境。
此外,新疆和田、山西太原、山東濟南、河北保定、安徽合肥等地的數據標注產業都在不斷成長。
貴州是全國首個大數據綜合試驗區,而惠水縣百鳥河數字小鎮也則是貴州首個縣級大數據產業園區。
目前,百鳥河數字小鎮已培育了迦太利華、金百合、黔南即富、夢動科技、金信大數據等重點企業。
其中,貴州夢動科技員工超過500人,其中的一半人,是附近盛華職業學院的學生。該公司曾入選2020全國數據標注公司排行榜前10強。
鄭成安是一名大三在校學生,目前在夢動科技實習,公司全職員工只有十多人,管理層大都是學校里的老師,對他而言上課就是上班,老師就是經理。
鄭成安出身農村,上高職前沒碰過電腦,現在憑借電腦前的兼職,一個月能拿到1500元以上的收入,他感到非常滿足。
有時候,他為了多掙一些生活費,碰上緊急的項目,會主動加班。但鄭成安很清楚,標注員的工作很難一直做下去。
2022年6月,美國加州圣馬特奧縣的特斯拉辦公室,200員工被裁員,其中大多數都是數據標注員。
裁員背后,是因為特斯拉正在研發計算機Dojo,采用自監督學習技術,用于訓練人工智能模型,對數據標注的需求正越來越低。
不僅如此,國內騰訊、阿里、字節跳動等一眾大廠都在研發自監督學習技術。
可以說,隨著人工智能的不斷成長,數據標注員的工作,也變得岌岌可危。這些曾經教會了人工智能“思考”的人,同樣正面臨被人工智能取代的風險。