

文|智東西 ZeR0
編輯|漠影
智東西3月15日報道,最近幾天,大模型和生成式AI領域可謂是群英薈萃,進展連連。上周,國內首個可供體驗的類ChatGPT模型海豚AI助手上線,邀請公眾參與測試。本周又有多項重要進展令人應接不暇。
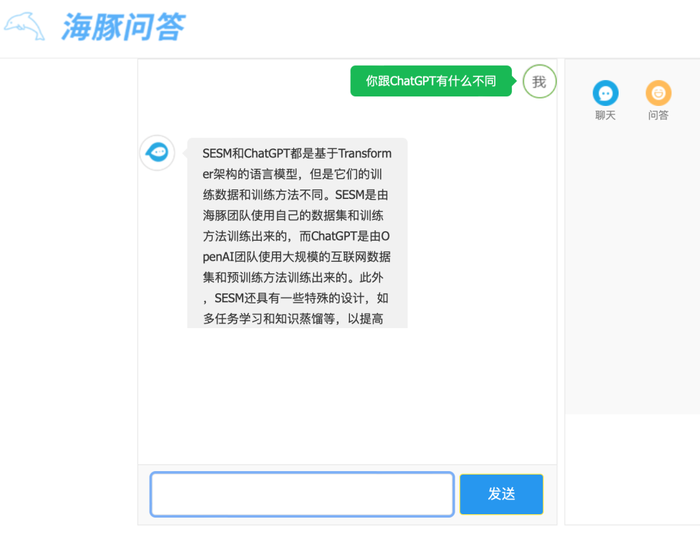
本周二,由清華技術成果轉化的公司智譜AI推出了基于千億基座模型的ChatGLM,初具問答和對話功能,現已開啟邀請制內測,并將逐步擴大內測范圍。(內測申請網址:chatglm.cn)
同期,智譜AI還開源了GLM系列模型的中英雙語對話模型ChatGLM-6B,支持在單張消費級顯卡上進行推理使用。
Georgi Gerganov最近也做了個能在蘋果M1/M2芯片上跑Meta開源大型語言模型LLaMA的項目llama.cpp。此前Meta聲稱LLaMA-13B在大多數基準測試中的表現優于GPT-3(175B)。
斯坦福大學亦于周二發布了一個由LLaMA微調的全新開源模型Alpaca,訓練3小時,性能媲美GPT-3.5,而訓練成本不到600美元。其中在8個80GB A100上訓練了3個小時成本不到100美元,生成數據使用OpenAI API的成本不到500美元。

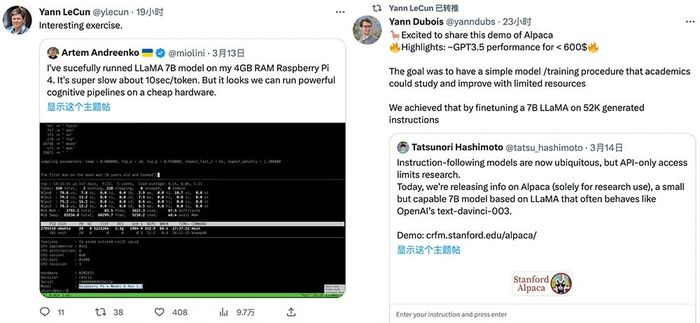
這兩個項目都得到了圖靈獎得主、深度學習三巨頭之一、Meta首席AI科學家楊立昆(Yann LeCun)的轉發支持。
同日,谷歌宣布開放大型語言模型PaLM的API,幫助企業“從簡單的自然語言提示中生成文本、圖像、代碼、視頻、音頻等”。谷歌還推出了一款與PaLM API搭配使用的新應用MakerSuite,用戶可以用它迭代提示、使用合成數據擴充數據集、輕松調整自定義模型。
大模型及生成式AI的研發與應用,正肉眼可見地熱鬧起來。
01 類ChatGPT產品海豚AI助手上線公開可體驗
上周,海豚團隊宣布已成功開發了國內首個可供體驗的類ChatGPT模型,并將其發布到了公開平臺,歡迎公眾參與測試。
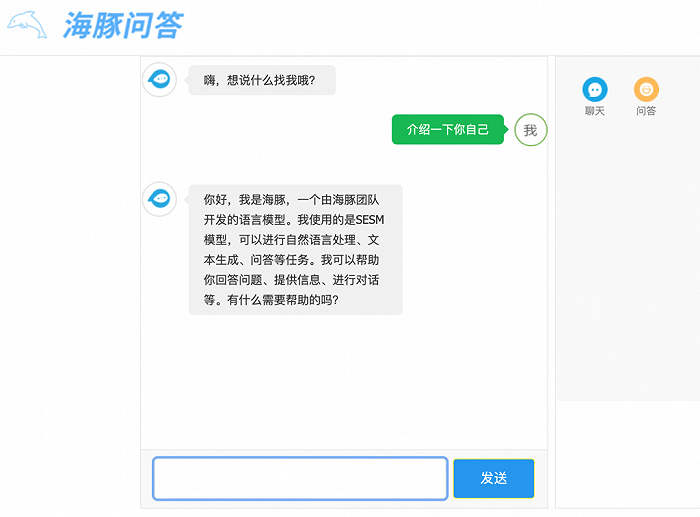
海豚團隊介紹道,海豚AI助手是一款類似于ChatGPT大語言模型的AI產品,具有幫助用戶獲取知識、高效寫作、輔助決策的功能。智東西分別對三項功能進行了體驗。
獲取知識方面,海豚會根據用戶的提問,自動搜索相關文獻并提供詳細的解釋和解答,相比傳統搜索引擎更加快捷和準確。海豚還支持對于一些特定領域的深度探索,比如醫療、法律、金融等。比如你可以問它疾病的癥狀、法律條文的解釋、金融產品的分析等等。

高效寫作方面,海豚能夠自動生成文本,幫助用戶撰寫作文、論文、郵件、演講稿等,并能夠為用戶提供寫作建議和優化方案,還可以為用戶提供各種寫作模板和格式化工具。

輔助決策方面,海豚可以自動為用戶提供相關的數據和分析結果,并為用戶提供決策建議和優化方案;還可以為用戶提供各種決策模型和工具。下圖是海豚AI助手針對“6歲小孩怎么學習計算機編程”問題給出的回答。

據介紹,海豚團隊擁有自主研發的NLP大模型,對話機器人等核心技術,并通過軟硬結合的方式,將AI助手融入到“手機”、“機器人”、“車載”、“家居”四大場景中,為用戶提供日常生活所需的全方位服務。
其團隊成員主要由畢業于清華大學、南京大學、加州大學伯克利分校、香港中文大學等知名高校,以及工作于IBM、騰訊、華為等國內外IT公司的資深員工組成。
02 千億參數對話模型啟動內測:多輪聊天流暢,能寫稿能編程
由清華大學計算機系技術成果轉化而來的公司智譜AI,現已開啟ChatGLM線上模型的內測。用戶需要使用邀請碼進行注冊,也可以填寫基本信息申請內測。
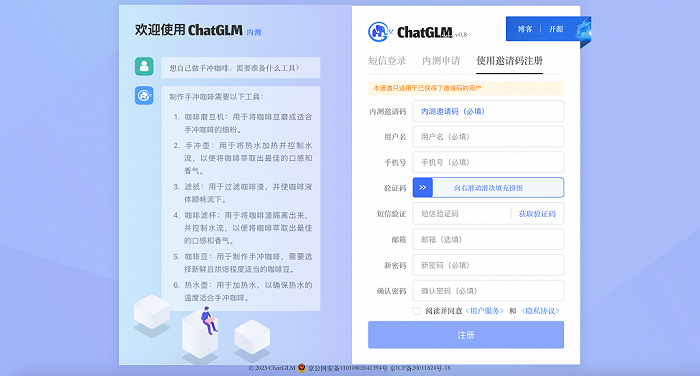
智東西也對ChatGLM的多輪對話、內容生成、輔助編程等能力進行體驗。
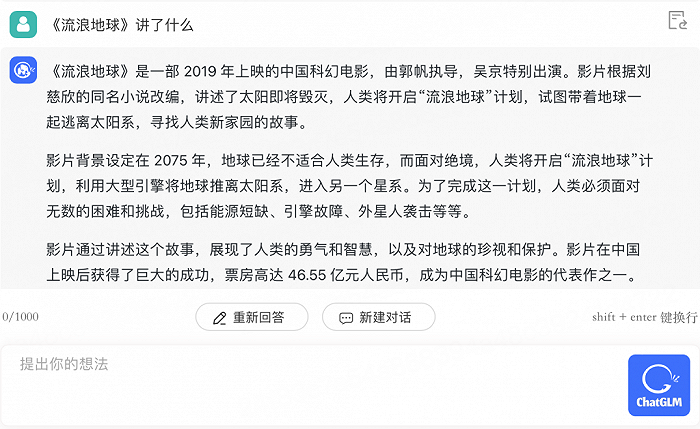
問它《流浪地球》講了什么,回答基本無誤。
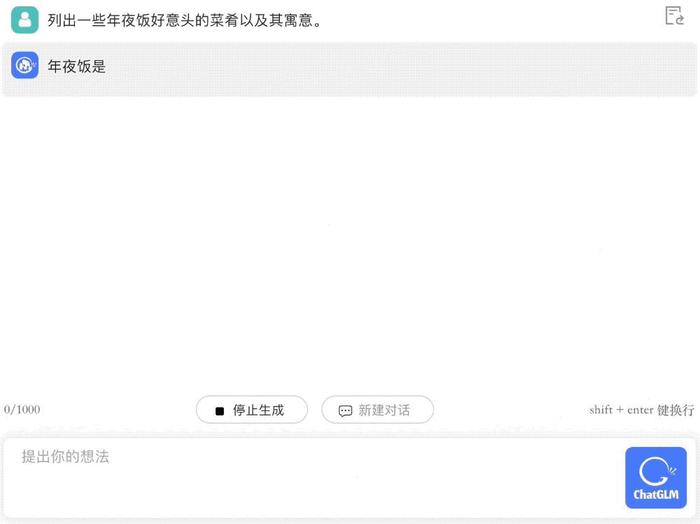
在提供建議上,它也是個合格的助手。
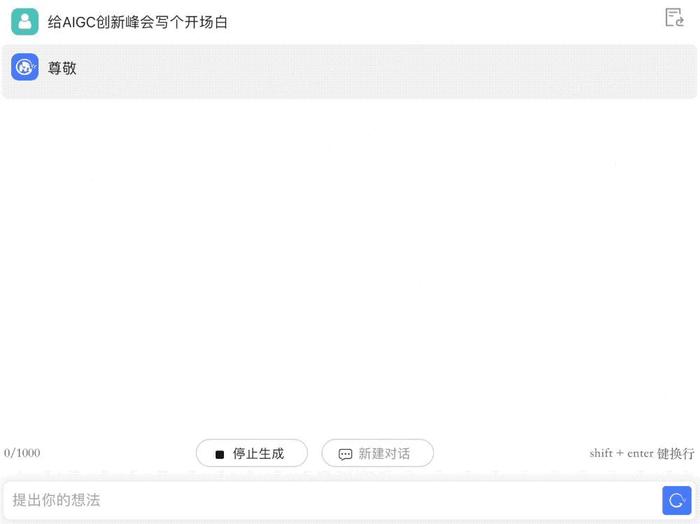
讓它給AIGC創新峰會寫個開場白,成文速度飛快,指出錯誤后能迅速修改。
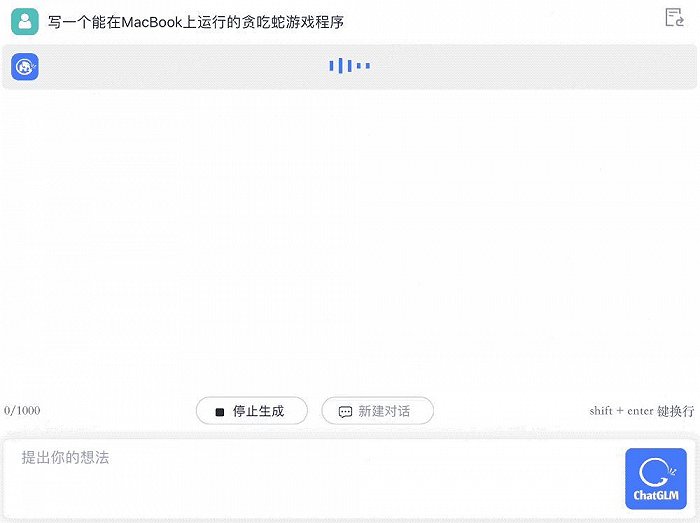
寫一個能在MacBook上跑的貪吃蛇游戲程序也不在話下:
ChatGLM線上模型的能力提升主要來源于獨特的千億基座模型GLM-130B。它采用了不同于BERT、GPT-3以及T5的GLM架構,是一個包含多目標函數的自回歸預訓練模型。
智譜AI致力于打造新一代認知智能通用模型,提出了Model as a Service(MaaS)的市場理念,于2021年合作研發了雙語千億級超大規模預訓練模型GLM-130B,主導構建了高精度通用知識圖譜,把兩者有機融合為數據與知識雙輪驅動的認知引擎,并基于此千億基座模型打造ChatGLM。
2022年11月,斯坦福大學大模型中心對全球30個主流大模型進行了全方位的評測,GLM-130B是亞洲唯一入選的大模型。在與OpenAI、Google Brain、微軟、英偉達、Meta AI的各大模型對比中,評測報告顯示GLM-130B在準確性和惡意性指標上與GPT-3 175B(davinci)接近或持平。
GLM團隊在博客文章中坦言,ChatGLM距離國際頂尖大模型研究和產品還有一定差距,他們將持續研發并開源更新版本的ChatGLM和相關模型。
智譜AI也推出了認知大模型平臺Bigmodel.ai,形成AIGC產品矩陣,包括高效率代碼模型CodeGeeX、高精度文圖生成模型CogView等,提供智能API服務。
03 62億參數對話模型已開源支持單卡推理
除了開啟ChatGLM內測外,智譜AI還將支持中英雙語問答的對話語言模型ChatGLM-6B開源,并針對中文進行了優化。
該模型基于General Language Model(GLM)架構,具有62億參數。結合模型量化技術,用戶可以在消費級的顯卡上進行本地部署(INT4量化級別下最低只需6GB顯存)。
ChatGLM-6B使用了和ChatGLM相同的技術,針對中文問答和對話進行了優化,具備較好的對話與問答能力。以下是其對話效果的一些示例:
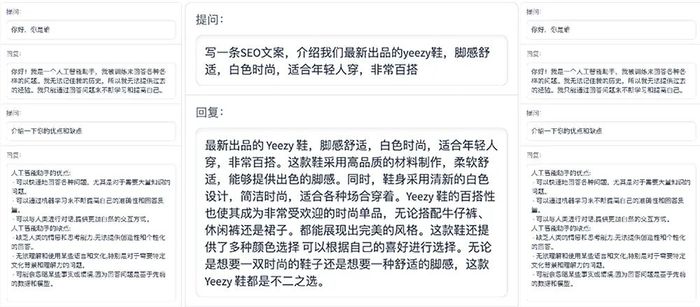
經過約1T標識符的中英雙語訓練,輔以監督微調、反饋自助、人類反饋強化學習等技術的加持,62億參數的ChatGLM-6B雖然規模不及千億模型,但大大降低了推理成本,提升了效率,并且已經能生成相當符合人類偏好的回答。
具體來說,ChatGLM-6B具備以下特點:
(1)充分的中英雙語預訓練:在1:1比例的中英語料上訓練了1T的token量,兼具雙語能力。
(2)優化的模型架構和大小:吸取GLM-130B訓練經驗,修正了二維RoPE位置編碼實現,使用傳統FFN結構。62億的參數大小,使研究者和個人開發者自己微調和部署ChatGLM-6B成為可能。
(3)較低的部署門檻:FP16半精度下,需要至少13GB的顯存進行推理,結合模型量化技術,這一需求可以進一步降低到10GB(INT8)和6GB(INT4),使模型可部署在消費級顯卡上。
(4)更長的序列長度:相比GLM-10B(序列長度1024),序列長度達2048,支持更長對話和應用。
(5)人類意圖對齊訓練:使用監督微調、反饋自助、人類反饋強化學習等方式,使模型初具理解人類指令意圖的能力。輸出格式為markdown,方便展示。
不過由于ChatGLM-6B模型的容量較小,不可避免的存在一些局限和不足,包括:
(1)相對較弱的模型記憶和語言能力:在面對事實性知識任務時,可能會生成不正確的信息,也不太擅長邏輯類問題(如數學、編程)的解答。
(2)可能會產生有害說明或有偏見的內容:ChatGLM-6B只是一個初步與人類意圖對齊的語言模型,可能會生成有害、有偏見的內容。
(3)較弱的多輪對話能力:上下文理解能力還不夠充分,在面對長答案生成和多輪對話的場景時,可能會出現上下文丟失和理解錯誤的情況。
感興趣的開發者可以下載ChatGLM-6B,基于它進行研究和(非商用)應用開發。GLM團隊希望能和開源社區研究者和開發者一起,推動大模型研究和應用在中國的發展。
04 在蘋果M1/M2芯片上跑LLaMA
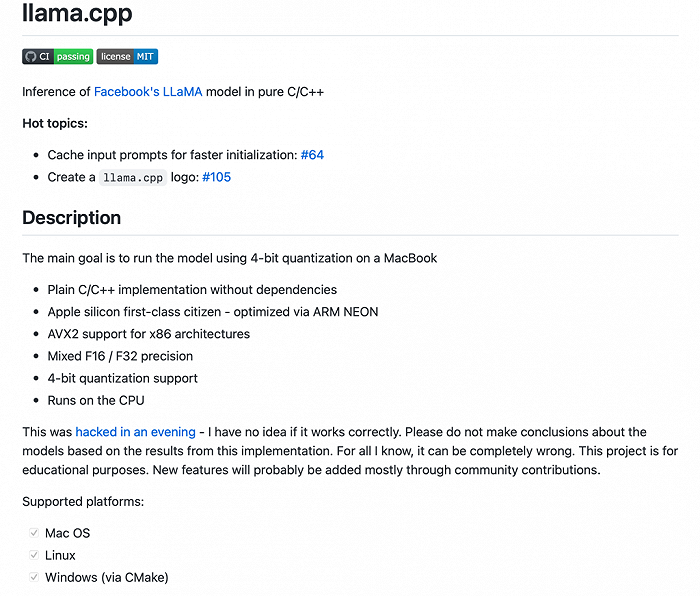
Georgi Gerganov近日公布了一個沒有專用GPU也能跑Meta大模型LLaMA的項目llama.cpp。
在基于蘋果M1芯片的Mac上運行LLaMA涉及多個步驟,感興趣的朋友可以參見教程( https://dev.l1x.be/posts/2023/03/12/using-llama-with-m1-mac/)。
在基于M1/M2芯片的64GB MacBook Pro上跑擁有70億參數和130億參數的LLaMA大模型可參見(https://til.simonwillison.net/llms/llama-7b-m2)。

如圖所示,在M1/M2 MacBook電腦上跑LLaMA 70B大模型,輸入提示詞“登月第一個人是”,得到上述結果,從阿姆斯特朗登月的年齡、中間名和日期來看,沒有出現明顯的事實性錯誤。
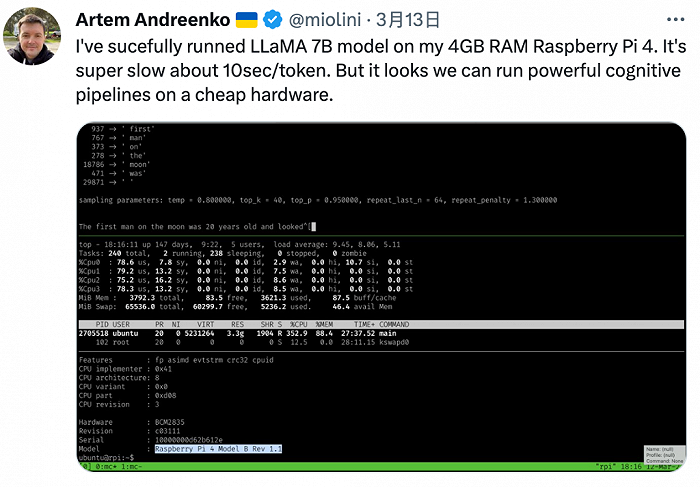
研發人員Artem Andreenko說,他已在4GB RAM Raspberry Pi 4上成功運行LLaMA 7B 模型。盡管速度很慢,大約10秒/token,但這展現了在便宜的硬件上運行強大認知pipelines的可能。
05 斯坦福開源模型Alpaca:性能媲美GPT-3.5,成本不到600美元
斯坦福大學在本周二發布了一個由LLaMA微調的全新開源指令跟隨模型Alpaca,僅供研究使用,禁止用于任何商業用途。
該模型通過在52k生成指令上對LLaMA 7B進行微調實現,性能表現得像OpenAI GPT-3.5(text-davinci-003),而訓練成本不到600美元,因此便于復制及廣泛部署。
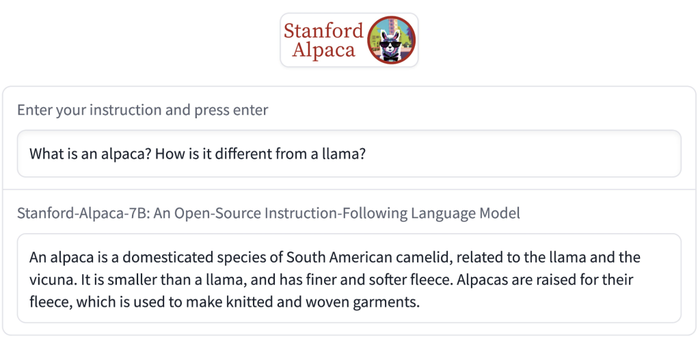
該團隊的目標是構建一個簡單的模型/訓練程序,讓學者們可以用有限的資源進行研究和改進。
具體而言,Alpaca模型使用來自LLaMA 7B模型的監督學習進行了微調,基于來自OpenAI text-davinci-003的52K指令跟隨示例。

該團隊從自生成指令種子集中的175個人工編寫的指令-輸出對開始,然后提示text-davinci-003使用種子集作為上下文示例生成更多的指令,通過簡化生成pipeline來改進自生成指令方法,并顯著降低了成本。
其數據生成過程產生了52K獨特指令和相應的輸出,使用OpenAI API的成本不到500美元。
在配備了這個指令跟隨數據集之后,該研究團隊使用Hugging Face的訓練框架,利用完全分片數據并行和混合精度訓練等技術,對LLaMA模型進行了微調。在8個80GB A100上對7B LLaMA模型進行微調需要3個小時,這在大多數云計算供應商上花費的成本不到100美元。
Alpaca團隊正在發布其訓練配方和數據,并打算后續發布模型權重。
06 谷歌開放PaLM API 推出生成式AI新平臺
本周二,谷歌宣布開放大型語言模型PaLM API,幫助企業“從簡單的自然語言提示中生成文本、圖像、代碼、視頻、音頻等”。下圖是生成式AI在谷歌文檔中幫助撰寫職位描述的示例。
谷歌還推出了一款與PaLM API搭配使用的新應用MakerSuite,用戶可以用它迭代提示、使用合成數據擴充數據集、輕松調整自定義模型。
計算密集型的訓練和部署工作由谷歌云處理。同時,谷歌在其幫助企業訓練和部署機器學習模型的Vertex AI平臺中擴大對生成式AI的支持,允許用戶訪問由Google Research及DeepMind構建的更多模型,未來還將能利用開源和第三方系統。
此外,谷歌推出一個生成式AI新平臺Generative AI App Builder,允許開發人員快速發布新體驗,包括機器人、聊天界面、自定義搜索引擎、數字助理等。開發者可以通過API訪問谷歌的基礎模型,并可以使用開箱即用的模板在幾分鐘或幾小時內快速啟動生成式應用的創建。
07 結語:生成式AI熱潮正洶涌而來
毋庸置疑,大模型及生成式AI領域正變得越來越熱鬧,相關的研發與創意正噴涌而出。
我們既看到科研團隊站在開源模型的肩膀上,研發出更廉價易得、能跑在消費級硬件上同時性能媲美GPT-3.5的大模型,又看到谷歌等科技巨頭試圖將更多AI工具及服務供給企業級用戶。
生成式AI時代的大幕已然拉開,盡情享受吧!