
編譯|智東西 程茜
編輯|心緣
智東西2月25日報道,圍繞生成式AI的前沿技術競爭愈發膠著。就在昨晚,Meta突然公布了一款全新的AI大型語言模型LLaMA,宣稱可幫助研究人員降低生成式AI工具可能帶來的“偏見、有毒評論、產生錯誤信息的可能性”等問題。
此前在最新季度財報電話會議中,Meta CEO扎克伯格提到“生成式AI”的次數比“元宇宙”還要多。如今,Meta帶來了一個利好研究學者的AI重磅成果——僅用約1/10的參數規模,實現了匹敵OpenAI GPT-3、DeepMind Chinchilla、谷歌PaLM等主流大模型的性能表現。

Meta介紹LLaMA論文
Meta目前提供有70億、130億、330億和650億四種參數規模的LLaMA模型。
根據論文,在一些基準測試中,僅有130億參數的LLaMA模型,性能表現超過了擁有1750億參數的GPT-3,而且能跑在單個GPU上;擁有650億參數的LLaMA模型,能夠跟擁有700億參數的Chinchilla、擁有5400億參數的PaLM“競爭”。
要知道,GPT-3是AI聊天機器人ChatGPT背后大模型GPT-3.5的前代,GPT-3.5的參數量也高達1750億;而谷歌驅動對話式AI應用Bard進行搜索查詢的模型,參數量比5400億還要多。
這是大模型研究邁出的重要一步!隨著技術持續優化,未來有朝一日,你也許能在自己的筆記本電腦乃至手機上跑類ChatGPT功能的語言模型。
扎克伯格說,LLaMA“在生成文本、進行對話、總結書面材料以及解決數學定理或預測蛋白質結構等更復雜的任務方面表現出了很大的潛力”。
扎克伯格Facebook貼文
值得一提的是,Meta宣布LLaMA基礎大型語言模型“開源”,不作商用目的,免費供給研究人員。目前Meta在GitHub上提供了精簡版LLaMA。
01 擁有70-650億參數,20種語言訓練
LLaMA作為一種基礎大型語言模型,相比于GPT-3等模型,其可以讓開發人員使用更少的計算能力和資源來進行測試。
目前,科技巨頭玩家在大型語言模型領域開展軍備競賽,并且有多個成果面世。但研發人員在運行此類大模型時往往需要大量的資源投入,導致部分開發人員并不能全面研究訪問這些模型。
而這種限制就會阻礙人員去理解這些模型的工作模式和功能,并且使得他們在調整模型的偏見、發生錯誤的可能性上會較為困難。
作為一個基礎模型,LLaMA不是為特定任務而設計,Meta研究人員通過標記一些Tokens等來訓練基礎模型,其優勢在于更容易針對特定潛在產品應用進行再訓練和微調。
不同于Chinchilla、PaLM、GPT-3等大模型,LLaMA只使用公開可用的數據集進行訓練,其中包括開放數據平臺Common Crawl、英文文檔數據集C4、代碼平臺GitHub、維基百科、論文預印本平臺ArXiv等。項目成員稱,這是為了使其工作與開源兼容和可復現。
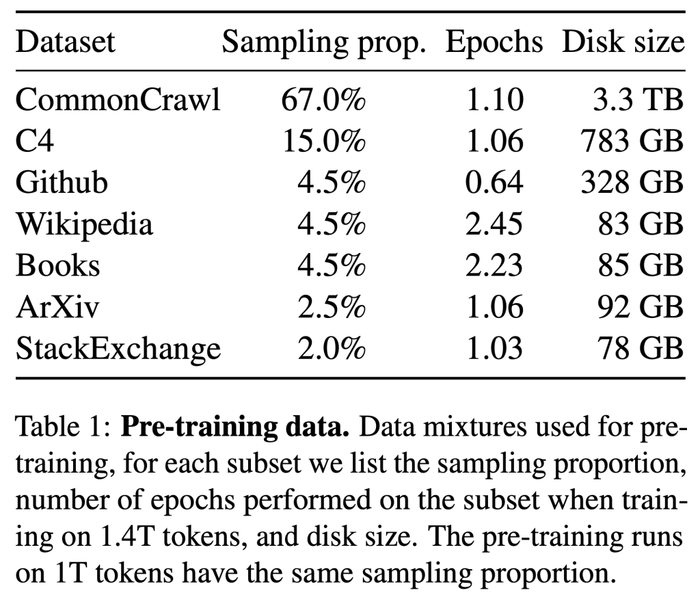
總體來看,整個訓練數據集在標記化后大約包含1.4萬億個Tokens。
其中,擁有650億參數的LLaMA和擁有330億參數的LLaMA使用1.4萬億Tokens進行訓練,最小的擁有70億參數的LLaMA在1萬億Tokens上進行了訓練。
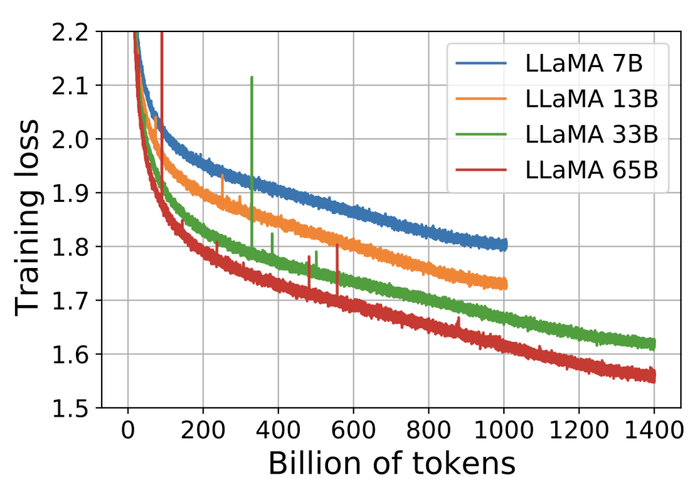
擁有不同參數的模型與訓練損失的關系圖
與其他大型語言模型一樣,LLaMA的工作原理是將一系列Tokens作為輸入,并預測下一個單詞以遞歸生成文本,Meta使用了20種語言對其進行訓練。
此外,大型語言模型中還可能會遇到生成偏見、不良信息、不實信息的風險,基于共享LLaMA的代碼,其他開發人員可以測試限制或消除大型語言模型中這些問題的方法。
02 7項AI能力,不輸業界主流大模型
在測試過程中,研究人員采用0-shot和1-shot、5-shot、64-shot幾種方式,將LLaMA與GPT-3、Gopher、Chinchilla等模型進行了比較。
尤其值得一提的是,130億參數LLaMA模型在單個GPU上運行時,性能表現可能超過1750億參數GPT-3。這也許會給類ChatGPT產品跑在消費級硬件上打開新的大門。
1、常識推理(Common Sense Reasoning)
LLaMA涵蓋了八個標準常識性數據基準,包括BoolQ、PIQA等。這些數據集包括完形填空、多項選擇題和問答等。
結果顯示,擁有650億參數的LLaMA在BoolQ以外的所有報告基準上均超過擁有700億參數的Chinchilla。同時,除BoolQ和WinoGrande外,該模型測試中均超過擁有5400億參數的PaLM。
擁有130億參數的LLaMA模型在大多數基準測試上也優于擁有1750億參數的GPT-3。
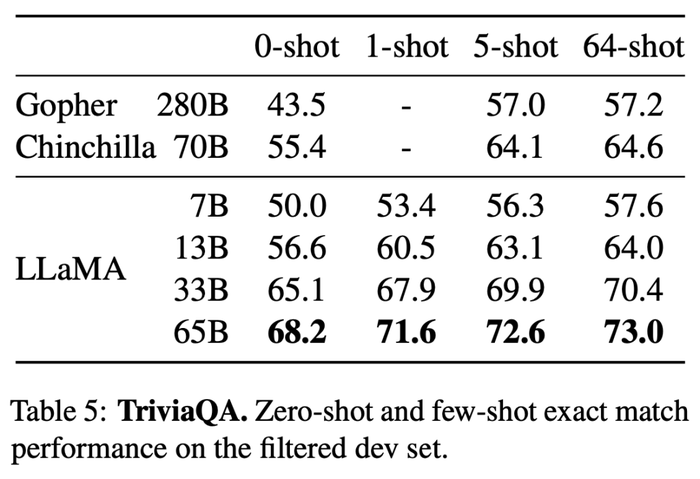
2、閉卷問答(Closed-book Question Answering)
研究人員就閉卷答疑對LLaMA進行了測試,該基準測試的數據集包含閱讀理解與問答的大規模語料集TriviaQA以及自然問題。
擁有650億參數的LLaMA在0-shot和1-shot條件下,實現了較好的性能。
在推理過程中,擁有130億參數的LLaMA在一個V100 GPU上運行,其基準測試結果顯示,與GPT-3和Chinchilla不相上下。
3、閱讀理解(Reading Comprehension)
在閱讀理解能力方面,LLaMA通過大型深層閱讀理解任務數據集RACE評估,擁有650億參數的LLaMA與擁有5400億參數的PaLM相差并不大。
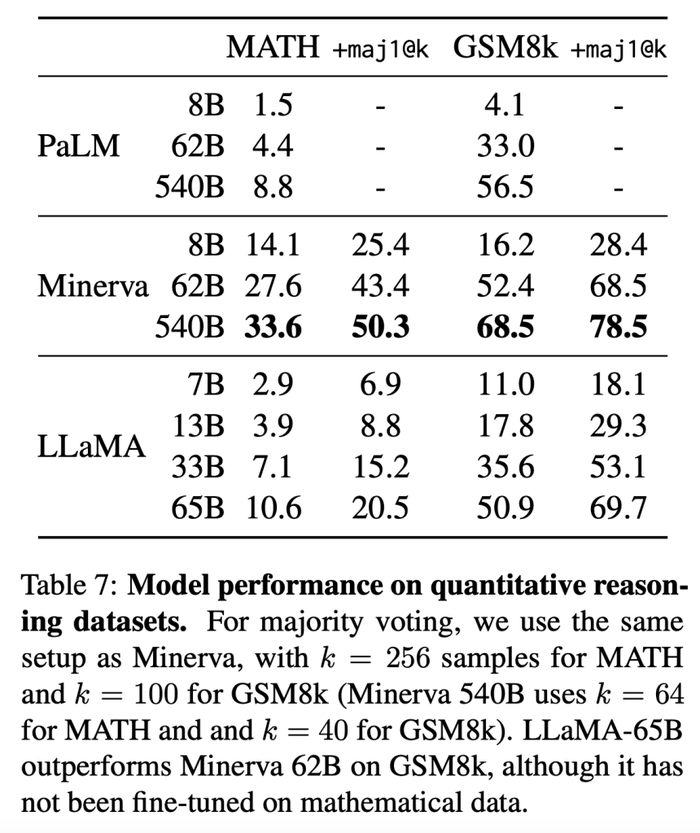
4、數學推理(Mathematical reasoning)
研究人員根據兩個數學基準評估LLaMA模型,分別是包含中學和高中數學問題的數據集MATH、OpenAI發布的小學數學題數據集GSM8k。
其比較模型對象是,從ArXiv和Math Web Pages提取的擁有385億數據進行微調的PaLM模型Minerva。
結果顯示,在GSM8k上,擁有650億參數的LLaMA優于擁有620億參數的Minerva。
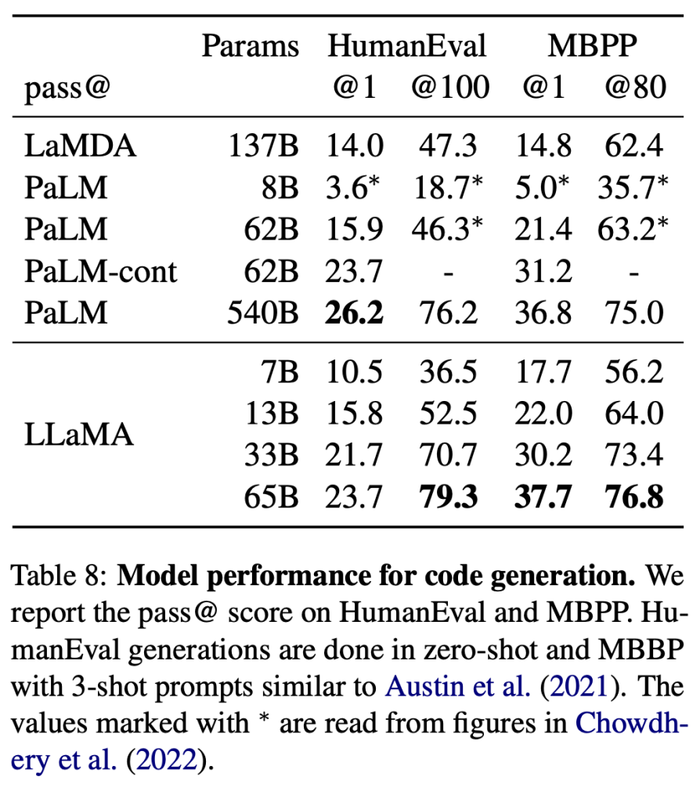
5、代碼生成(Code generation)
基于編程代碼開源數據集HumanEval和小型數據集MBPP,被評估的模型將會收到幾個句子中的程序描述以及輸入輸出實例,然后生成一個符合描述并能夠完成測試的Python程序。
對于擁有相似參數的模型,LLaMA優于其他通用模型。
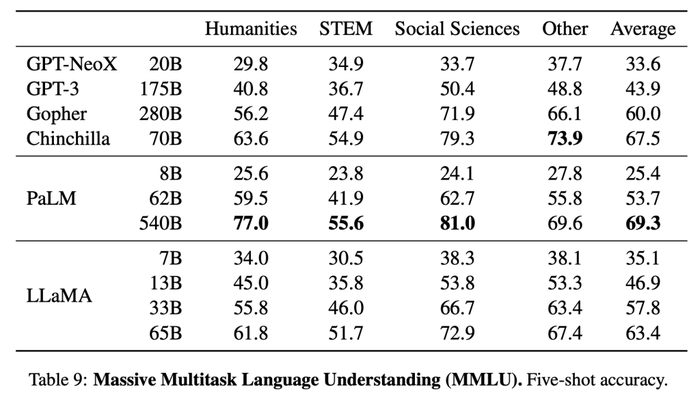
6、大規模多任務語言理解(Massive Multitask LanguageUnderstanding)
這一數據集基準涵蓋人文科學、STEM、社會科學等各種知識領域的多項選擇題。
經比較,研究人員發現,擁有650億參數的LLaMA在大多數領域平均落后于擁有700億參數的Chinchilla和擁有5400億參數的PaLM幾個百分點。
研究人員猜測,其中一個可能的原因是,他們在訓練前使用的數據集較為有限,包括177GB大小的ArXiv、Gutenberg和Books3,而其余模型的訓練數據足有2TB大小。
7、訓練期間的能力進化(Evolution of performance during training)
在訓練過程中,研發人員跟蹤了LLaMA在一些問題回答和常識性基準上的表現,其都保持穩步提高。
不過針對于相關數據集的評估,研究人員認為其存在許多性能差異,該基準的結果并不可靠。
03 去年曾發布Galactica大模型但因偏見和造假火速下架
關于大模型的研究如今在AI領域十分火熱。其基本原理就是通過獲取新聞、社交媒體或其他互聯網資源上的文本,來訓練軟件,使得基于大模型生成的產品可以在用戶給出提示或查詢搜索時自行預測和生成內容,其目前最直觀的例子就是最近爆火的聊天機器人ChatGPT。
也正由于這一現象級消費級應用的推動,使得科技巨頭開始構建基于大模型的產品測試,并將生成式AI視作新競爭領域。
年初,微軟向聊天機器人ChatGPT的創造者OpenAI投資了數十億美元,隨后,微軟推出了其ChatGPT版新Bing搜索引擎。谷歌很快也加入競賽,該公司基于其大型語言LaMDA推出類似的對話式AI應用程序Bard。
去年5月,Meta也曾發布了擁有1750億參數的OPT大型語言模型,這一模型的適用對象也是開發人員,是生成其聊天機器人BlenderBot的基礎模型。半年后,Meta推出名為Galactica的語言模型,該模型可以撰寫科學文章并解決數學問題,但在推出三天后,這一模型就因經常胡言亂語以及給出虛假信息被撤下。
國外投資機構DA Davidson高級軟件分析師Gil Luria認為:“Meta今天的公告似乎是測試他們生成式AI能力的一步,這樣他們就可以在未來將它們應用到產品中。”
他還補充道:“生成式AI作為AI的一種新應用,Meta對此經驗較少,但顯然對其未來的業務很重要。”
04 結語:生成式AI競賽不斷升溫
大型語言模型已經在生成創意文本、解決數學問題、預測蛋白質結構、回答閱讀理解問題等方面展示出了巨大的潛力,如今ChatGPT的發布使得其在消費級應用市場中爆發。
繼微軟、谷歌之后,Meta也試圖在這一領域展現自己的技術優勢。
在科技大廠紛紛亮出生成式AI商用計劃之時,Meta難得地聚焦在研究貢獻上,無論是用更多數據訓練出的更少參數規模模型實現優于更大參數規模模型的研究成果,還是將LLaMA模型和權重開源開放,都令人感到耳目一新。
但也由于僅限于研究用途,這可能導致Meta短期內難以在生成式AI領域形成像OpenAI、谷歌那樣的影響力。