

文|甲小姐
本文導讀:
1.功能性vs人格化:兩種本質相反的牽引力
2.不用可信vs必須可信:少部分人細思恐極,大多數人惶然而不自知
3.真命題vs假命題:AGI不是一個好命題
4.商業價值vs商業模式:發明電燈的人不一定直接享受到電力革命的紅利,卻依然值得歌頌

5.理論潔癖vs暴力美學:長期信仰來自深刻理性
6.有意瞄準vs無意擊發:一場企業家精神對科學界的反哺
1.功能性vs人格化:兩種本質相反的牽引力
ChatGPT作為史上界面最樸素卻圈粉最快的科技產品,給人的沖擊感不是發生在眼球層面,而是顱內層面的。
火到“上頭”背后有兩重原因:
一方面是功能性的勝利,如幫人們寫作文、編程、收集結構化資料,其內容生成的速度和質量甚至超出很多在AI行業深耕多年的從業者的預期;
另一方面是人格化的勝利,它會理解意圖、聲明立場、表達恭喜、道歉、自我修正答案,并擁有上下文的記憶連貫性,體現出實時的自主學習能力,簡言之,就是“像人”。
打個比喻,因為渴望飛行又沒有翅膀,人類造出了飛機。一直以來,AI界一直在“造飛機”,之前各類突破性進展都讓飛機的功能性越來越強,而ChatGPT卻似乎造出了一只“鳥”。這也是為什么ChatGPT被很多從業者定位為“通用人工智能(AGI)”雛形的原因。
功能性與人格化看似在這一代ChatGPT上得到了平衡,但從本質看,二者有著相反的牽引力。
如果追求功能性,重點是回答本身的正確、精準、靠譜,最好其回答有明確的可溯源的出處。排除寫作文等本來就需要發揮創意的功能,不同人問同一個問題應該有類似的答案(千人一面),因為大部分功能性問題是在尋求正確解或最優解。這更像“改進版搜索引擎”,New Bing就是這么做的,這有其明確的價值,卻不是革命性的體驗;
如果追求人格化,重點是交互感、創新性、超預期,意味著不能有死記硬背的感覺,因為死記硬背并不是人類學習與交互的慣性方式,這意味著回答要有個性、豐富性、多樣性甚至狡猾性。
詭異的地方恰恰在于,后者往往比前者看起來更“聰明”,更“機靈”,但往往更“不可信”。
在今天版本的ChatGPT中,你可以輕易誘導它犯錯,而且它會犯許多出乎你預料的錯,有的回答會一本正經地胡說八道,有的回答會陷入滔滔不絕的“廢話文學”,但由于它的表達方式足夠討巧,會認錯、道歉,會自我“澄清”,因此這甚至讓你感到開心、好玩、可愛——ChatGPT正是以人格化特征建立了用戶心理的“容錯性”,而這也是為什么人格化相比功能性是今天ChatGPT大火更顯著的助燃劑(大家紛紛在朋友圈曬問答,被分享的段落絕大部分是ChatGPT表現出情商的片段、超預期的部分、搞錯的部分)。
在諸如“評價一下甲子光年”這樣的問題中,ChatGPT的回答是帶有狡猾性與迎合性的。如果你在對話前文表達了對甲子光年的認可,ChatGPT馬上就會附和,是一個機靈的捧哏,但換個人再問,回答立刻變成不知道——ChatGPT只是在當前對話中根據用戶反饋進行修正,當我們重啟一個對話,測試相同的問題時,ChatGPT會表現出失憶或犯錯。
從原理看,今天的ChatGPT之所以給人一種很強的“理解力”,是因為ChatGPT是“重新表達”材料,而不是從數據庫中逐字引用,這讓它看起來像一個學生用自己的話表達思想,而不是簡單地重復它讀過的東西。
“重新表達”和搜索是兩件事——正是因為這種“重新表達”,造成了ChatGPT“理解”了材料的“錯覺”。
然而,舉一反三和胡編亂造間有一個微妙的界限,這個界限在人與人之間的對話中往往也是模糊的。這就引發了一個關鍵問題:ChatGPT可信嗎?
什么是可信?如何辨別其回答是否可信?這些問題背后,還有一個前置性問題:ChatGPT的一系列延伸價值和未來想象,是否需要建立在“可信”的基礎上?
2.不用可信vs必須可信:少部分人細思恐極,大多數人惶然而不自知
很多人想當然地以為,現在不夠“可信”,是因為模型還不夠大、數據還不夠多、技術還不夠強,或者是因為缺乏安全技術與監管手段,這是對“可信”的理解還不夠透徹。
內容分兩種,一種的本質屬性不依賴“可信”,一種的本質屬性必須“可信”。
前者往往是kill time(消磨時間)類型內容,核心是抓住用戶的時間,占領時間越多越好,用戶越上癮越好。典型代表是今日頭條、抖音、各類游戲。字節系諸多產品最初都以放棄可信度換取UGC的海量內容,以個性化取代了絕對權威,以“最適合的”取代了“最優解的”。文章視頻從相對高門檻的作者生產、編輯分配,變成相對低門檻的用戶生產、算法分配,構建了算法推薦的世界;
后者往往是save time(節省時間)類型內容,核心是準確、科學、實用、工具屬性,典型代表是搜索引擎、維基百科。很多人近來逐漸減少在搜索引擎上投入的時間,轉而去知乎甚至B站搜索,也恰恰是因為商業導流的泛濫和各巨頭間內容圍墻的普遍存在,搜索結果正變得沒那么可信、沒那么直接。
對準確性有強訴求的人群將很快發現,如果無法保證ChatGPT的可信度,而對生成內容的校驗方式又需要回歸到搜索引擎,或者需要溯源內容出處以做再判斷(New Bing就是以羅列出處鏈接的方式來嫁接回答內容與可信出處),其價值將大打折扣。試想,如果ChatGPT每一次給我的回答,我都要交叉驗證,那不是多此一舉嗎?
特德·姜在《ChatGPT是網上所有文本的模糊圖像》一文中寫道:“任何對內容工廠有好處的東西都不適合搜索信息的人。”他用壓縮算法做了一個類比:如果一種壓縮算法被設計成在99%的原始文本被丟棄后重建文本,我們應該預料到,它生成的很大一部分內容將完全是捏造的。
換言之,需要kill time的人和需要save time的人往往是兩撥人。需要個性化生成式內容的人和需要搜索引擎的人的本質訴求是不同的。前者是“1到正無窮”,需要創意和與眾不同,不存在“最優解”;后者是“無窮中尋一”,需要精確、準確、正確,要無限逼近全局最優解。
ChatGPT是為了kill time而生還是save time而生呢?兩條路都有巨大的商業前景,都不可怕,但最可怕的是:你似乎是可信的,但其實不然。最怕的是你以一種看似可信的方式,出現在了需要可信的場景,卻交付了不可信的內容。
當然,一個自然的問題是:能不能既要也要呢?能不能在消除不可信的同時,保留人格化、創意化的天馬行空的部分?這是一個目前業界各類產品都未能驗證的期待。
可信意味著可記錄、可驗證、可追溯、可審計,而這很可能與大模型理念的本質就是沖突的。我們在昨天的文章里寫到,考慮到安全隱患,ChatGPT的發布公司,OpenAI,在安全保護機制方面對ChatGPT進行了較多限制,ChatGPT似乎正因此處于一種“情緒崩潰”的狀態。(見《第一批因ChatGPT坐牢的人,已經上路了|甲子光年》)
我之所以這么早強調“可信”這一點,是因為隨著大型語言模型生成的文本在網絡上發布得越多,網絡整體的信息質量就變得越模糊。伴隨信息過載,可信愈發困難,而“可信”這個問題越晚一天解決,就越難解決。用我同事涂明的話說,就是“其實信權威和信機器沒什么兩樣,如果機器個性化更強,最后就可能變成信自己,信息極化。”
從“個性化捧哏”到“個性化忽悠”只隔著一層窗戶紙。少部分人細思恐極,大多數人惶然而不自知——難道出路在于“每個人都是自己獲取信息的第一責任人”?
3.真命題vs假命題: AGI不是一個好命題
前文提到,ChatGPT被很多從業者定位為“通用人工智能(AGI)”,因為從產品效果來看,ChatGPT的智能水平已經表現出某種人類心智的特征,有人格化屬性,有靈動的“有機感”。我們知道有機物和無機物最本質的區別是有機物含碳,但AGI與非AGI的邊界卻沒有這么清晰。
為什么?因為AGI本身就不是一個真命題、好命題。
字面意義理解,AGI為“通用人工智能”,而什么是通用?什么是智能?人腦算通用嗎?文理科生的思維邏輯與知識儲備差異極大,從字面意義理解,人腦也不算通用智能。從沃爾夫假說來看,語言是思維的映射,母語英語的人和母語中文的人,本身思維方式就呈現出巨大的不同,腦補能力也不同。
那么,什么是“理解”?
如果一個大語言模型已經編譯了大量學科術語之間的相關性,多到可以對各種各樣的問題提供合理的回答——我們是否應該說它實際上理解了該學科?
這是一個哲學命題,我的答案是,能表現得理解,就是理解。
關于“理解”乃至“意識”,人類自己也始終沒有精準定義。我們做AI,并不是要從原理到外在復刻一個人類大腦,只要表現出人類對話的外在特征,就可以定義為理解與表達。(否則還能怎么辦呢?)
有很多網友質疑ChatGPT并非強人工智能,理由無非是“ChatGPT雖然能夠做到XXX,但是它并沒有理解”,這種質疑相當于是在爭辯“如果一個智能被機器實現了,就不能被叫做智能”,這是悖論不是辯論。或者說,今天爭論ChatGPT是“強人工智能”還是“弱人工智能”,也許不是一個真問題。
一個更務實的問題是:這個“9歲兒童”的智能會在“18歲成年”時長成什么樣子?其極限在哪里?
圣塔菲研究所前所長Geoffrey West在科普書《規模》中揭示了規模法則(scaling law)。在West眼中,有一種不變的標準可以衡量看似毫無關聯的世間萬物——無論是生物體的體重與壽命,還是互聯網的增長與鏈接,甚至是企業的生長與衰敗,都遵循規模法則。規模法則關心復雜系統的特性如何隨著系統大小變化而變化。
以規模法則的視角看待ChatGPT背后的大模型,一個自然的問題是:模型一定是越大越好嗎?如果數據量足夠大、算力足夠充沛,是否AI的效果會無限上揚?
面對這個問題,業界多方的答案是Yes and No。
持Yes觀點的人認為,現在的“大”并不足夠大。
從歷史角度看,上世紀60年代,圖靈獎獲得者馬文·明斯基在批判第一代神經網絡時,認為它所需要的計算量很大,當時他說的“大”指的是數十KB。如今看來,這種規模是極小的。試想一下,在二十年后,今天的大模型是否還能稱之為大模型呢?
從用腳投票角度看,不同公司的LLM(Large Language Model,大語言模型)基本都是基于Transformer構建的自回歸、自我監督、預訓練、密集激活模型,他們接連表現出驚人的能力,證明了more is different。
從內容類型角度看,目前ChatGPT還是針對文本對話或者寫代碼,下一步一定會拓展到圖像、視頻、音頻等多模態,乃至逐步納入AI for Science、機器人控制等領域,這是通往AGI的必經之路,目前只是剛剛開始,在短期的未來,當然要一鼓作氣地做“大”。
持No觀點的人認為,大模型雖好,但其性能有一個上限,雖然這個上限尚不明確。
從通用性的角度看,目前的基礎大模型不會選擇根據低頻數據更新參數,否則大模型就會因為對某些長尾數據進行過擬合而失去通用性。
從專有領域的角度看,硬件在進行推理時,往往無法承載超規模的預訓練模型,人們需要針對具體應用進行模型的裁剪和優化。此外,專有領域也不一定需要超大規模的模型,不恰當的網絡架構也許會造成對計算資源極大的浪費。值得一提的是,GPT-3 之所以取得了非常好的效果,并不僅僅是是因為“大”,也包括他們找到了一種“提示”的方法,這些方法也可以應用到非常小的模型上。
從數據供給的角度看,《Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning》(P Villalobos, J Sevilla, L Heim, T Besiroglu, M Hobbhahn, A Ho [University of Aberdeen &MIT &Centre for the Governance of AI &University of Tübingen] (2022) )的估算結論是到2026年左右,高質量的NLP數據將會用光,低質量NLP數據會在2030到2050年用光,而低質量圖像數據會在2030到2060年用光。
這意味著:要么到時我們有新類型的數據源,要么我們必須增加LLM模型對數據的利用效率。否則,目前這種數據驅動的模型優化方式將會停止進步,或者收益減少。
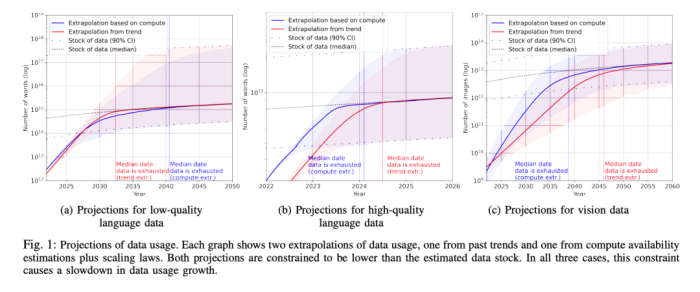
此外還有一些問題:我們還沒有充分使用已有的數據;超大規模模型的調優問題還沒有被解決;如何從預測任務邁向決策任務……一個最本質的問題是,是否給出足夠的時間、足夠的錢、足夠的數據,所有問題最終都能夠被大模型解決?大模型的極限在哪里?
比爾·蓋茨評價ChatGPT出現的重大歷史意義不亞于互聯網和個人電腦的誕生,這個表述究竟是否高估,與大模型這條能力曲線的走勢息息相關。
4.商業價值vs商業模式:發明電燈的人不一定直接享受到電力革命的紅利,卻依然值得歌頌
另一種對ChatGPT的普遍擔憂是成本問題。
有網友表示:“訓練大型人工智能模型的成本已在數量級上逼近人類愿意拿出來的最大成本,若人類的總功率增量不能加速,模型參數的持續增長無法加速。”
對此,我更認同理想汽車CEO李想在朋友圈的表達:“搜索引擎公司看待ChatGPT的成本,和燃油車企業早期看電動車的成本如出一轍。他們都在想:這么高的成本,咋盈利呀?”
今天,用成本與收益的角度來評價ChatGPT為時過早。對于突破性技術進展而言,從一開始就以商業維度來考量似乎有失公允,質疑ChatGPT燒錢,類似于質疑探索航天事業燒錢。
首先,AI行業本身就有工業界反哺科學界的特征。類似ChatGPT這種邁向AGI之路的探索看似發生在工業界,但其價值本身是外溢出商業范疇的,是科學進展的重要組成部分。發明電燈的人不一定直接享受到電力革命的紅利。但如果撥開時光機回到過去:是不是應該鼓勵發明電?
其次,就算在商業語境范疇內看待這項技術,如果一項技術的成本只是時間問題,如果可以證明其成本隨著時間推移會逐漸降低到合理值,那么這就不是一項技術在早期階段需要被挑戰的“主要矛盾”。新興技術的賬怎么算,我個人的觀點是,更需要去看這條道路的第一性原理,而不是過去、現在、未來幾年燒不燒錢,能不能賺錢。
再次,ChatGPT離賺錢沒那么遠。以ChatGPT對程序員的助力為例:依據GitHub的數據,2021年,中國有755萬程序員,排名全球第二。放眼全球,程序員數量已經超過7300萬,比2020年增長了1700萬。根據預測,2025年GitHub上的程序員估計能達到1億。這里面,隨便幾個百分點的降本增效,都是一個巨大的市場空間。此外,大家很關注ChatGPT對搜索引擎的替代,但另一個巨大的市場是office類產品、在線文檔類產品和ChatGPT的融合——如果能夠讓寫word、做Excel、畫PPT的效率提升50%,我會毫不猶豫給甲子光年全員開通付費賬號。
一直以來,我都認為“商業價值”與“商業模式”是兩件事。商業模式有兩種,一種是人為事先設計的,另一種是做好商業價值之后伴生而來事后總結的,偉大的公司往往是先有商業價值而后有商業模式,而不是相反。對于技術突破而言,模式永遠是結果而非原因。在本該求因的階段求果,可能抓錯了主要矛盾,也喪失了戰略機遇。至少,我國AI距離世界最先進水平的差距并不是財力。當然,考慮到成本問題,未來也許會出現“股份制大模型”,多方群策群力,共建超級平臺,這都是“術”層面的問題。
5.理論潔癖vs暴力美學:長期信仰來自深刻理性
托馬斯·庫恩在《科學革命的結構》中提出,科學進步的軌跡是跳躍式的。科學通過“革命”的方式進步,通過擺脫那些遭遇到重大困難的先前世界框架而進步。這并非一種朝向預定目標的進步。它是通過背離那些既往運行良好、但卻不再能應對其自身新問題的舊框架而得以進步。
這個角度看,我們無疑正在經歷一場關鍵的科學革命。相比于其他學科以及早年間的AI派系,今天的AI行業更趨近于一場集體的范式遷移,這是由底層哲學觀牽引的。
ChatGPT背后的GPT系列體現了LLM應該往何處去的發展理念。很多人開始相信,揭開AGI的真正鑰匙正在于:超大規模及足夠多樣性的數據、超大規模的模型、充分的訓練過程。這條道路看似樸素,卻足以讓AI表現出智能“涌現”的能力,未來也許會持續帶來意想不到的驚喜和驚嚇。這種思想簡言之就是將“參數至上和數據至上”的思想發揮到極致,從細分技術“分而治之”到“大一統、端到端”,從理論潔癖走向暴力美學。
OpenAI并非這種哲學的奠基者。1956年達特茅斯會議首次提出“AI”概念后,AI路徑之爭、派系之爭始終存在。自深度學習誕生以來,AI行業的發展越來越像是一個暴力的擬合機器,多次里程碑節點都來自于LLM模型規模的增長,而非突破性理論的推動(當然不能說大模型沒有突破性技術,只是這種技術的實現路徑不是理論潔癖者所甘心的畫風,比如做超大規模的LLM模型對技術團隊的工程實現能力要求是非常高的,仿佛“馴獸師”一般,包含無數技巧、臟活累活)。
ChatGPT之所以到達今天的高度,是OpenAI堅持信仰的結果。OpenAI基本堅定地把LLM看做是通往AGI的一條必由之路。2018年OpenAI提出GPT模型,在風頭不如BERT的情況下,再次提出GPT-2模型;隨著Google提出T5模型之后,再次提出GPT-3模型,今天依然在同樣的路徑上矢志不渝。
這頗有“以凡人之身軀領悟天之意志”的決絕感。大部分人都是因為看見才相信,OpenAI對技術判斷的前瞻性和其篤定信念是黃金一樣可貴的東西。
我的觀點是:信仰一定不是憑空產生的,信仰是需要對問題的深刻認知才會產生。OpenAI看似瘋狂,卻一定不是無腦all in。我一直相信長期信仰(而非短期狂熱)的背后是深刻的理性。
此外值得一提的是,今天的熱潮正在推動著國內很多宣傳與決策的快速跟進,這種跟進往往是建立在認知還沒有清晰之前,這很容易導致“走偏”。我個人并不期待AI的發展需要全球走向完全相同的路徑。這不僅容易偏廢,也會導致產業的脆弱性——人各有志,AI為何不可多樣性呢。就算是直接對標效而仿之,每一次彎道超車也要清醒論證,否則可能不是彎道超車,而是彎道翻車。
6.有意瞄準vs無意擊發:一場企業家精神對科學界的反哺
最后說點題外話,這次ChatGPT的爆發,讓我想起了八個字“有意瞄準,無意擊發”——這八個字用來形容狙擊手。你需要像狙擊手一樣專注,朝對的方向,心無旁騖地瞄準,至于兔子什么時候出來、槍什么時候會響,只是時間問題。
歷史是在鐘擺聲中進步的。回顧人類文明發展史,在古代,人們還沒有掌握萬有引力定律和牛頓定律之前,可能會直接記錄下物體各種運動現象,用眼睛而非邏輯去研究星星,而萬有引力定律和牛頓定律之后,方法自然不一樣了。打個比方,人們通過觀測、記錄來研究星星,正如大模型;人們發現萬有引力定律,就是理論突破。大模型→理論突破→大模型→理論突破,文明進步總是在螺旋中上升。當理論越強,對模型的依賴越小。
感謝ChatGPT在歲末年初交付關鍵一役,業界已經冰冷太久。此時此刻的全球科技產業界士氣大漲,就這一點而言,OpenAI已是功不可沒。自我2015年開始寫和AI相關文章開始,冷冷熱熱也經歷了好幾輪。ChatGPT再次驗證了科技行業的不變真理——高估低估常有,但永遠沒有蓋棺定論的一天。
科技行業永遠需要鯰魚。ChatGPT與其說是熱點,更應該定位為拐點。所以,無論ChatGPT的高溫天氣能持續多久,我都愿意為其添一把火——這是一場企業家精神對科學界的反哺,一場好久不見的暴力美學,一場技術信仰的勝利。