
文|芯東西 ZeR0
編輯|漠影
芯東西10月1日消息,今日上午,在第二屆特斯拉AI Day上,特斯拉分享了其自研Dojo超級計算機系統的更多技術進展,并公布未來路線圖。

據介紹,特斯拉首款人形機器人“擎天柱”的大腦就將采用Dojo超級計算機系統。
在去年的首屆特斯拉AI Day上,特斯拉展示了其首款AI訓練芯片Dojo D1,以及基于該芯片構建的完整Dojo集群ExaPOD,用于執行AI訓練任務,為其上路車輛龐大的視頻處理需求提供支撐。
當前特斯拉已經擁有基于英偉達GPU的大型超算,以及一個存儲30PB視頻素材的數據中心。

特斯拉技術專家稱,特斯拉的車隊在日常行駛中積累了很多視頻片段,每個視頻有多幀圖像,需要14億幀才能訓練一個神經網絡,需要使用10萬個GPU工時。而特斯拉自研的Dojo超算,能夠提升30%的網絡訓練速度。
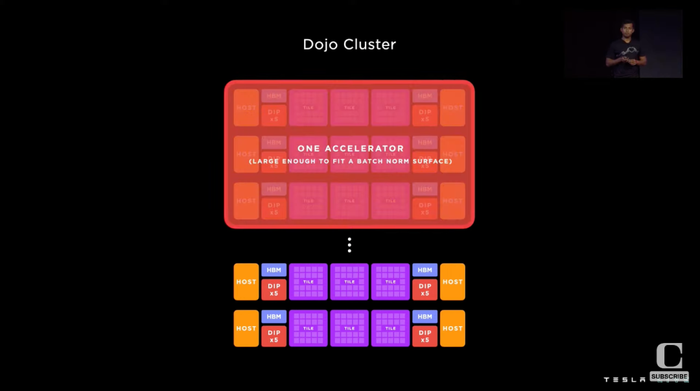
Dojo首席系統工程師Bill Chang說,特斯拉超級計算機的愿景是構建一個統一的加速器。
會上,Dojo團隊展示了通過Dojo實現Stable Diffusion在火星上運行Cybertruck的圖像。
據介紹,只用4個Dojo機柜就能取代由4000個GPU組成的72個GPU機架。Dojo能將通常需要幾個月的工作減少到了1周。

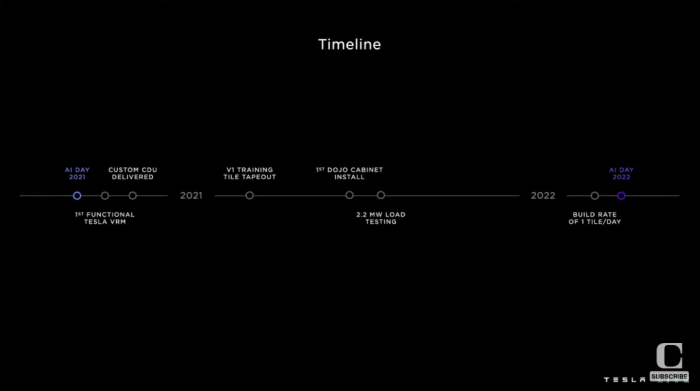
自去年特斯拉AI Day至今,Dojo開發迎來了一系列里程碑,包括安裝第一個Dojo機柜、進行2.2mW負載測試等,現在特斯拉正以每天打造一個Tile的速度推進工作。
特斯拉還宣布其第一個ExaPOD預計將在2023年第一季度完工,計劃在帕洛阿爾托總建造7臺ExaPOD。

01 快速試錯,看重熱膨脹系數
特斯拉一直試圖優化Dojo設計的可擴展性,并以“快速試錯”的心態來克服挑戰。
Dojo加速器具有單個可擴展計算平面、全局尋址快速存儲器和統一的高帶寬+低延遲。

Bill Chang特別談到電壓調節模塊,它具有高性能、高密度(0.86A/mm2)、復雜集成性。

其電壓調節模塊在24個月內更新了14個版本。
熱膨脹系數(CTE)很重要,因此特斯拉與供應商合作提供電力解決方案。其CTE降低了50%以上,Dojo的性能是初始擴展的3倍。

在Bill Chang看來,解決每個級別的密度是實現系統性能的關鍵,所有系統組件必須集成到電源模塊中。其集成解決方案包括用軟終端電容器來減少振動等。

特斯拉還展示了一組過去兩年間從交付定制冷液分配單元(CDU)到安裝第一臺集成Dojo機柜、再到2.2MW機組負載測試的照片。

02 秀Dojo系統全家福,首個ExaPOD明年完工
下圖是Dojo超級計算機系統,包括D1芯片、訓練Tile和ExaPOD集群。

D1采用臺積電7nm制程工藝,在645mm2的面積上塞了500億顆晶體管,BF16、CFP8算力可達362TFLOPS,FP32算力可達22.6TFLOPS,TDP(熱設計功耗)為400W。
相比之下,同樣采用臺積電7nm制程工藝、TDP達400W的英偉達旗艦計算卡A100 GPU,面積為826mm2,晶體管數量達542億顆,FP32峰值算力為19.5TFLOPS。
基于D1芯片,特斯拉推出晶圓上系統級方案,通過應用臺積電InFO_SoW封裝技術,將所有25顆D1裸片都集成到一個訓練Tile上,每個Dojo訓練Tile消耗15kW。特斯拉Dojo訓練Tile中有計算、I/O、功率和液冷模塊。

Dojo System Tray有高速連接、密集集成等特性,75mm高度能支持135kg。其BF16/CFP8峰值算力可達到54TFLOPS,功耗100+kW。

Dojo接口處理器是一個具有高帶寬內存的PCIe卡,利用特斯拉自家TTP接口。

特斯拉傳輸協議TTP還可以橋接到標準以太網,TTPOE可將標準以太網轉換至Z平面拓撲,擁有高Z平面拓撲連接性。

Dojo主機接口的介紹如下:

據介紹,在10機柜系統中,Dojo ExaPOD集群將突破E級算力。
其BF16/CFP8峰值算力達到1.1EFLOPS(百億億次浮點運算),并擁有1.3TB高速SRAM和13TB高帶寬DRAM。

03 對打英偉達A100,顯著降本增效
接下來是Dojo ExaPOD的軟件棧。

其軟件性能由硬件性能、利用率和加速器占用率的綜合加成決定。其中利用率涉及編譯器,加速器占用率涉及Ingest Pipeline功能。

在軟件方面,整個系統可以被視為一個整體。

借助Dojo編譯器,用戶可將Dojo大型分布式系統視作一個加速器。

現場,特斯拉首席工程師Rajiv Kurian分享了在Dojo上運行Stable Diffusion,根據“火星上Cybertruck”的提示創建由AI生成的圖像。他打趣道,看起來它在匹配特斯拉設計團隊之前還有很長的路要走。

Dojo編譯器的歸一化Batch Norm結果如下,相比GPU有數量級的延遲優勢。

同樣跑經典圖像分類模型ResNet-50,Dojo可以實現比英偉達A100更高的幀率。

跑自動標注算法、預測汽車周圍所有物體空間占用率的神經網絡模型Occupancy Networks時,相比英偉達A100,Dojo能實現性能的倍增。
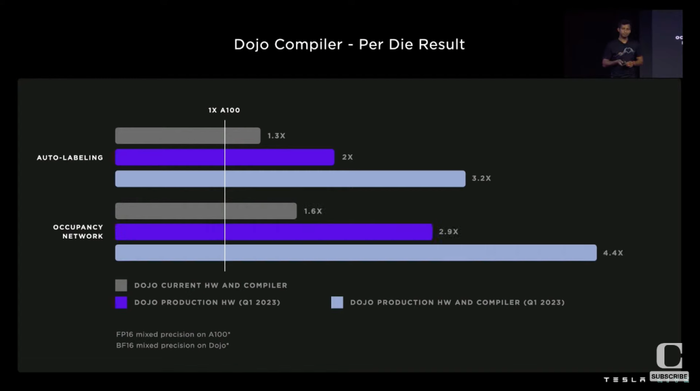
結果,以前要用6個GPU Box的計算開銷,現在不到1個GPU Box就能搞定。

72個GPU機架才能跑完的自動標注算法,現在只要4臺Dojo Cabinet機柜就能做到。


04 結語:特斯拉不止是一家汽車制造商
此前在為特斯拉AI Day預熱時,馬斯克已經發推文預告說此次活動的目的是為了招募人工智能和機器人領域的工程師,因此內容會非常硬核。
結果也如其所述,本屆AI Day儼然是特斯拉前沿技術能力的集中展示,從人形機器人的核心技術,到全自動駕駛(FSD)的各種先進算法,再到Dojo超算的軟硬件系統,干貨相當豐富。
從這些在人工智能、自動駕駛、機器人及計算硬件相關的技術布局,可以看到特斯拉在押注高精尖技術上的布局之深之廣,這也將是特斯拉吸引更多高端工程人才的絕佳金字招牌。