
文|芯東西 ZeR0
編輯|漠影
芯東西9月21日報道,昨夜,NVIDIA(英偉達)推出新一代GeForce RTX 40系列顯卡。
作為全球首款基于全新NVIDIA Ada Lovelace架構的GPU,RTX 40系列在性能和效率上都實現了巨大的代際飛躍。
其中,新旗艦產品RTX 4090 GPU的現代游戲性能相較上一代3090 Ti提升最高可達2倍,光線追蹤游戲性能的提升最高達到4倍,開大招DLSS 3后暢玩4K賽博朋克都不在話下。
英偉達創始人兼CEO黃仁勛在GTC大會主題演講的GeForce Beyond特別直播上介紹道,這意味著實時光線追蹤和利用AI生成像素的神經網絡渲染的新時代已然來臨。

首發的40系列有三款。旗艦產品RTX 4090 24GB將于10月12日上市,建議零售價12999元起。RTX 4080 16GB、RTX 4080 12GB將于11月上市,建議零售價分別為9499元起和7199元起。
相比之下,RTX 3090首發價是11999元起,RTX 3090 Ti首發價是14999元起,一臺頂配iPhone 14 Pro Max首發價是13499元。
這么一看,RTX 4090的性價比“真香”。

華碩、七彩虹、耕升、影馳、技嘉、映眾、微星和索泰等頂級顯卡供應商將在中國推出GeForce RTX 4090和4080 GPU標頻版和超頻版。RTX 40系列GPU還會通過宏碁、外星人、華碩、戴爾、惠普、聯想、微星等全球領先OEM的產品出售。
NVIDIA還將限量推出RTX 4090和RTX 4080(16GB)FE版,以滿足粉絲需求。
這些還只是GTC主題演講的“前菜”,同樣利用Ada Lovelace架構,英偉達面向自動駕駛計算推出了超級芯片DRIVE Thor,算力較上一代DRIVE Orin翻倍,浮點性能達2000 TFLOPS。
專為元宇宙應用打造的OVX計算機也升級至第二代,搭載了新Ada Lovelace L40數據中心GPU。
還有新款微型機器人計算機Jetson Orin Nano,速度比上一代Jetson Nano快了80倍。
此外,英偉達在今年4月面向數據中心發布的旗艦計算產品H100 GPU同樣迎來關鍵進展——全面投產。
面向元宇宙應用,英偉達還首次通過云服務進一步拓展其平臺的覆蓋范圍——發布英偉達首款軟件和基礎設施即服務(IaaS)產品Omniverse Cloud,為元宇宙應用的設計、發布、運營和體驗提供全面的云服務。

01 40系顯卡秒全場,臺積電定制版4N工藝
在將近25年前,英偉達推出了可編程著色GPU,GPU徹底改變3D圖形。
2018年,在全球計算機圖形圖像頂會SIGGRAPH上,英偉達推出全新GPU架構NVIDIA RTX,通過兩個全新處理器來擴展可編程著色器——RT Core用于加速實時光線追蹤,Tensor Core用于處理矩陣運算、加速AI。
今天,英偉達憋了4年的大招——第三代RTX架構Ada Lovelace,終于正式登場!
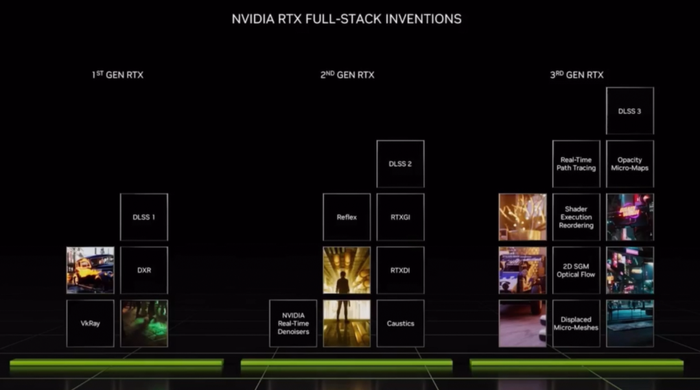
這代RTX以數學家Ada Lovelace的名字命名,她被公認為世界上第一位計算機程序員。
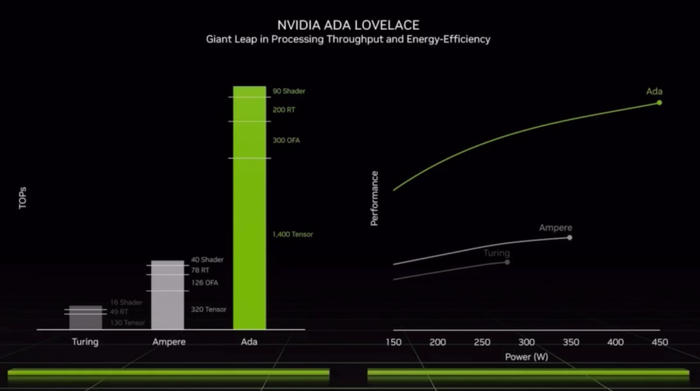
據介紹,Ada GPU可實現2倍的傳統光柵化游戲性能提升,對光線追蹤游戲的性能提升可以高達4倍。相較上一代Ampere架構,Ada在相同功耗下可帶來超過2倍的性能提升。
“Ada正在為完全基于仿真的未來游戲鋪路。”黃仁勛說。
今天英偉達推出的基于Ada Lovelace架構的GPU有三款:GeForce RTX 4090提供24GB版本,GeForce RTX 4080提供16GB和12GB版本。

GeForce RTX 4090 GPU是全新GeForce RTX 40系列的旗艦產品,是全球首款基于全新NVIDIA Ada Lovelace架構的游戲GPU。
RTX 4090擁有760億個晶體管、16384個CUDA核心和24 GB高速美光GDDR6X顯存,在4K分辨率的游戲中持續以超過100 FPS運行,在功耗、靜音、散熱等方面的提升都非常顯著。

在完整的光線追蹤游戲中,與前一代采用DLSS 2的旗艦GPU RTX 3090 Ti相比,采用DLSS 3的RTX 4090的性能提升可達4倍。
在現代游戲中,RTX 4090的性能提升高達2倍,同時保持了跟RTX 3090 Ti相同的450W功耗。
實現性能飆升的一個關鍵,是Ada引入了全新的NVIDIA DLSS 3超分辨率技術。該功能可在不影響畫質和響應速度的前提下,使用低分辨率內容作為輸入,并運用AI技術創造更多高質量幀。

黃仁勛說,玩像《賽博朋克2077》這樣的現代光線追蹤游戲,需對每個像素執行超過600次光線追蹤計算來確定光照,與4年前推出的首批光線追蹤游戲相比提升高達16倍。但GPU中負責此類計算的晶體管數量并沒有以同比增加,借助AI,英偉達在4年內將性能提升了16倍。
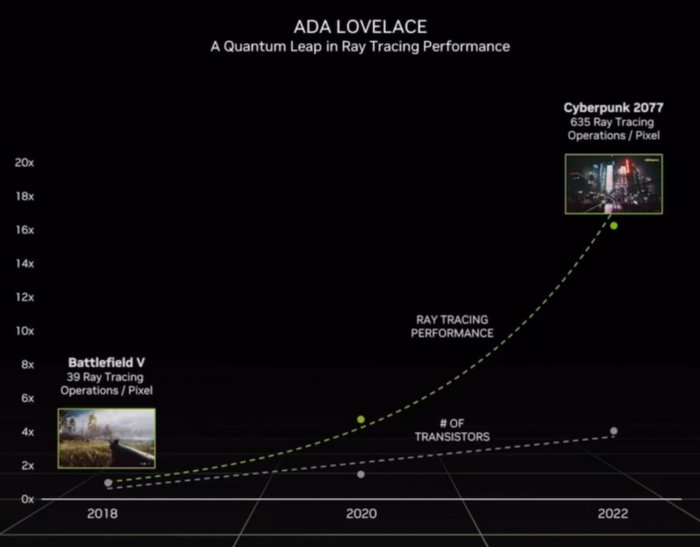
無論是對GPU性能要求較高的游戲,還是受到CPU限制的游戲,都將從該技術中受益。3D藝術家無需代理就可以利用精確的物理學和逼真的材料渲染完整的光線追蹤環境,并實時查看效果。
兩款次旗艦RTX 4080的配置則明顯跟RTX 4090拉開了差距。
RTX 4080 16GB擁有9728個CUDA核心和16 GB高速美光GDDR6X顯存,在現代游戲中的性能可達GeForce RTX 3080 Ti的2倍;在較低功率下,性能比GeForce RTX 3090 Ti更強。
RTX 4080 12GB擁有7680個CUDA核心和12GB 美光 GDDR6X顯存,性能跟3090 Ti同級。

02 7大技術創新,帶飛RTX 40系列性能
這次RTX 40系列GPU的性能大幅提升,背后有一系列技術創新的支撐。
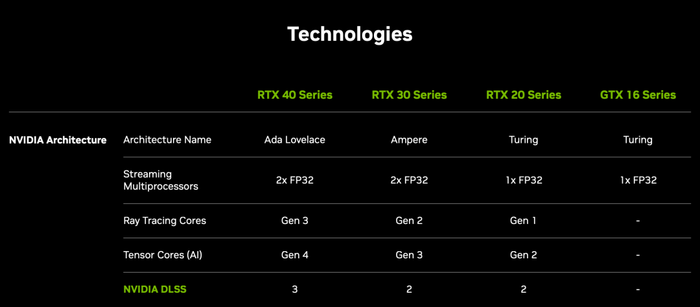
1、架構上的改進:英偉達與臺積電合作創建了針對GPU優化的4N定制工藝,使RTX 40系列能夠集成760億個晶體管、超過18000個CUDA核心,較上一代Ampere多了70%,性能功耗比提升高達2倍。
2、SM流式多處理器:具有高達90 TFLOPS的著色器能力,吞吐量超過上一代產品2倍。
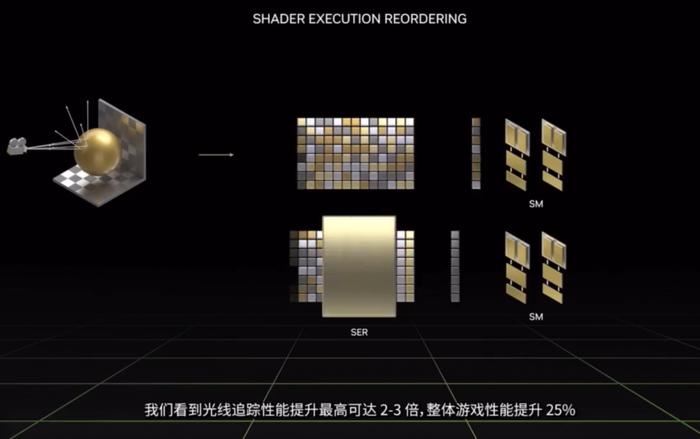
3、著色器執行重排序(SER):通過即時重新安排著色器負載來提高執行效率,從而更好地利用GPU資源。該技術可以實時重新調度任務,被黃仁勛稱作是“與CPU的亂序執行一樣的重大創新”,可將光線追蹤性能提升2-3倍,整體游戲性能提升25%。
4、第三代RT Cores:有效光線追蹤計算能力達到191 TFLOPS,是上一代產品2.8倍。
第三代RT Cores可提供2倍的光線與三角形求交性能,及兩個全新的重要硬件單元。Opacity Micromap引擎將光線追蹤的Alpha-Test幾何性能提升2倍;Micro-Mesh引擎可動態生成微網格,以產生額外的幾何圖形,可在提升幾何圖形豐富度的同時,不以傳統復雜幾何圖形處理的性能和存儲成本為代價。
5、第四代Tensor Cores:新增Hopper FP8 Transformer Engine,FP8張量處理性能高達1.4 Petaflops,超過上一代使用FP8加速性能的5倍。
6、Ada光流加速器:帶來2倍的性能提升,使DLSS 3能夠預測場景中的運動,使神經網絡能夠在保持圖像質量的同時提高幀率。
7、雙NVIDIA編碼器(NVENC)將輸出時間至多縮短一半,并支持AV1。OBS、Blackmagic Design DaVinci Resolve、Discord以及更多的公司都已在采用NVENC AV1編碼器。
03 2000 TFLOPS,最強自動駕駛超級芯片來了
在推出新一代自動駕駛芯片前,黃仁勛照例先回顧了一遍戰績:英偉達在2018年推出的Xavier是世界上第一款專為深度學習設計的機器人處理器,此后每隔兩年,英偉達就會發布性能飛躍的新一代處理器。去年,英偉達發布的Altan更是將峰值性能拉到了1000 TOPS。
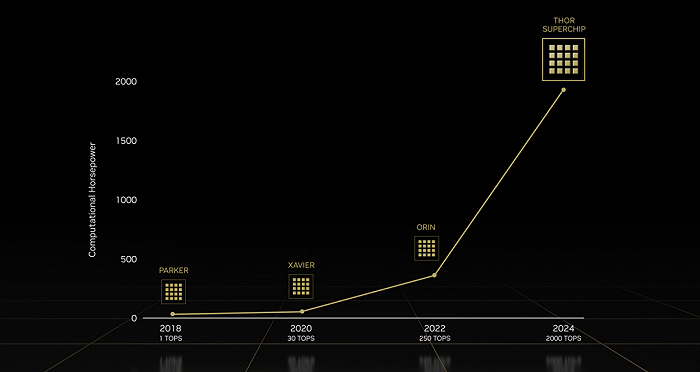
今天,黃仁勛放出新的大招——NVIDIA DRIVE Thor的吞吐量達到Atlan的2倍,整型峰值性能可達2000 TOPS,FP8精度的峰值性能可達到2000 TFLOPS,同時降低整體系統成本,目標是汽車制造商的2025年車型。
實現這一目標,得益于三個因素:Grace CPU、Hopper GPU和Ada Lovelace GPU。Hopper集成的Transformer引擎有助于加速計算,Ada中多實例GPU的發明將有助于車載計算資源的集中化,可將成本降低數百美元。

Thor可配置為多種模式,可將其算力全部用于自動駕駛工作流,或者將其中一部分用于駕駛艙AI和信息娛樂,另一部分用于駕駛員輔助。
Thor的多計算域隔離,使其允許并發的、對時間敏感的多進程無中斷運行。車輛可以在一臺計算機上,同時運行Linux、QNX和Android。
當前汽車的停車、主動安全、駕駛員監控、攝像頭鏡像、集群、信息娛樂等功能由不同的計算設備控制,未來這些功能可以統一由Thor支撐。

兩個DRIVE Thor還能利用最新的NVLink-C2C芯片互連技術“拼接”成一塊功能更強的芯片,作為運行單個操作系統的整體平臺。
回到英偉達第二代機器人處理器DRIVE Orin上,Orin已經被40多家汽車、卡車、無人駕駛出租車和穿梭巴士的制造公司采用。自動駕駛汽車的基本處理流水線可應用于各種機器人系統。
Jetson系列是英偉達打造的機器人計算機,擁有100萬開發者,在本屆GTC大會上,黃仁勛宣布推出一款微型機器人計算機Jetson Orin Nano,速度比上一代Jetson Nano快了80倍。

有移動的機器人,也有觀察移動物體的機器人系統。英偉達邊緣AI平臺Metropolis的下載量已達100萬次,在全球擁有1000多家應用合作伙伴。Orin還是Metropolis運行所在的工業級IGX Edge AI平臺的機器人處理器。
全球大型工業自動化公司西門子將Metropolis和Orin IGX用于其工業邊緣計算平臺。
除了機器人開發外,Orin IGX也是醫療影像應用的理想計算平臺。在Orin IGX上運行的NVIDIA Clara Holoscan是一個低延遲的成像處理平臺,包含用于數據處理、AI模型訓練、仿真和機器人開發應用的庫。70多家領先的醫療設備公司、創企及醫療中心都在Clara Holoscan上進行開發。

Activ Surgical、Proximie和Moon Surgical將在運行于Orin IGX平臺的NVIDIA Clara Holoscan上構建其手術機器人系統。
04 劍指元宇宙:第二代OVX計算機升級Ada架構,推出首款Iaas云服務
面向元宇宙應用,黃仁勛宣布推出第二代OVX計算機,由全新Ada Lovelace L40數據中心GPU和增強的網絡技術提供支持,以提供突破性的實時圖形、AI和數字孿生模擬功能。

借助48GB超大幀緩沖區,擁有8個L40 GPU的第二代OVX將能完成超大的Omniverse虛擬世界仿真。L40 GPU已全面進入量產。第二代OVX系統將于明年年初向市場提供。
除了元宇宙專屬硬件外,英偉達還打造了其首款IaaS產品Omniverse Cloud服務,可連接在云、本地或設備上運行的Omniverse應用。個人或團隊可以借助該服務一鍵體驗設計和協作3D工作流程的能力,而無需任何本地計算能力。
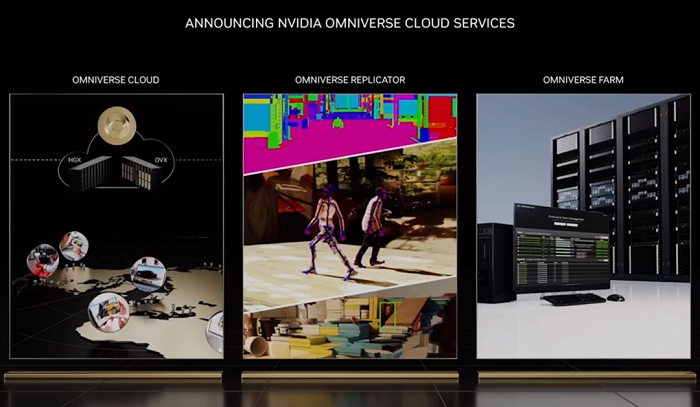
新的Omniverse容器現已可用于云部署,包括用于生成合成數據的Replicator、用于擴展渲染農場的Farm、用于構建和訓練AI機器人的Isaac Sim等。
英偉達為自主移動機器人打造的Isaac平臺進入云端后,用戶可在NGC上獲取云就緒的Omniverse VMI虛擬機鏡像和Isaac容器,并將其部署到任何公有云上。
05 從云端到超算,H100全面投產
最后,我們來看一下面向數據中心和高性能計算的加速計算最新進展。
黃仁勛說,NVIDIA平臺現已擁有350萬名開發者,12000家創企正基于英偉達的產品開創新業務,英偉達通過550個SDK和AI模型為約3000個應用提供加速。“總體來說,我們所服務的各行業總價值約為100萬億美元。”
面向數據中心,英偉達在今年4月發布的最新旗艦產品H100 Tensor Core GPU已經進入大規模量產。
H100包含800億個晶體管,采用了全新Hopper架構、Transformer引擎、第二代多實例GPU、機密計算、第四代NVIDIA NVLink互連、DPX指令等多種創新技術,能夠被用于加速高級推薦系統、大型語言模型等超大規模的AI模型訓練。

據介紹,H100使企業能夠削減AI的部署成本,相較于上一代A100,在提供相同AI性能的情況下,可將能效提高3.5倍,總體擁有成本減少至1/3,所使用的服務器節點數也減少至1/5。
英偉達全球技術合作伙伴計劃于10月推出首批基于NVIDIA Hopper架構的產品和服務,到今年年底預計將有超過50款服務器型號面市,2023年上半年還將有數十款型號面市。
AWS、谷歌云、微軟Azure、Oracle Cloud Infrastructure將從明年開始率先在云端部署基于H100的實例。數家全球領先的高等教育和研究機構的新一代超級計算機也將采用H100。
DGX H100系統現在即可訂購。該系統FP8精度的峰值性能可達到32 PFlops。每個DGX系統都包含NVIDIA Base Command和NVIDIA AI Enterprise軟件,可實現從單一節點到NVIDIA DGX SuperPOD的集群部署。
在軟件支持上,H100現包含為期五年的NVIDIA AI Enterprise軟件套件許可,這將優化AI工作流程的開發部署,確保用戶可獲得構建AI聊天機器人、推薦引擎、視覺AI等所需的AI框架和工具。
一些全球領先的大型語言模型和深度學習框架正在H100上進行優化,這些框架與Hopper架構相結合,能夠顯著提升AI性能,將大型語言模型的訓練時間縮短到幾天乃至幾小時。
06 推出兩種大型語言模型云服務,助攻生物醫學研究
大型語言模型(LLM)是當今最重要的AI模型之一。借助LLM,用戶只需通過較少的樣本來精調模型,就能高效執行特定任務。Hopper架構則有助于降低LLM的訓練及部署門檻。
今天,英偉達推出Nemo LLM云服務,用于訓練大型語言模型。
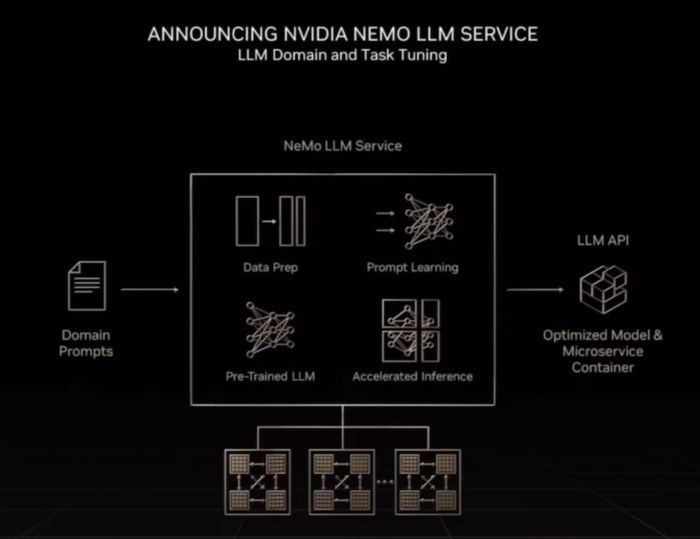
Nemo包含社區構建的一系列預訓練基礎模型,其API可生成習得的提示embedding表和優化的微服務,可部署在本地、云中,適用于一個GPU或者多個GPU、多個節點。現在注冊,10月就能搶先體驗這項服務。
英偉達還推出了BioNeMo LLM服務,用于訓練和部署超算規模的大型生物分子語言模型。
領先的制藥公司、生物技術初創企業和前沿生物研究人員正在使用BioNeMo LLM服務和框架來開發用于生成、預測和理解生物分子數據的AI應用,從而更好地了解疾病,并找到治療方法。
NVIDIA BioNeMo LLM服務將提供4個預訓練語言模型:
1、ESM-1:這一最初由Meta AI Labs發布的蛋白質LLM能夠處理氨基酸序列,最終生成用于預測各種蛋白質特性和功能的表征。它還提高了科學家理解蛋白質結構的能力。
2、OpenFold:這是由學術界和產業界共同成立的Openfold聯盟創建的sota蛋白質建模工具,可通過BioNeMo服務提供其開源AI工作流程。
3、MegaMolBART:這一基于14億分子訓練而成的生成式化學模型可用于反應預測、分子優化和新分子的生成。
4、ProtT5:該模型是在慕尼黑工業大學RostLab的帶領下合作開發的,NVIDIA也是該項目的參與者之一。PortT5將ESM-1b等蛋白質LLM的功能擴展到序列生成。
這些模型針對推理進行了優化,并將通過NVIDIA DGX Foundry上運行的云端API提供搶先體驗。

07 結語:英偉達已成為一家全棧式計算公司
英偉達在1999年發明的GPU,激發PC游戲市場的增長、重新定義了計算機顯卡并助燃了現代AI普及的浪潮。此次新推出的Ada Lovelace一代GPU,改進了作為神經渲染引擎的全部三個RTX處理器,對于游戲玩家、虛擬世界創作者都帶來了新的生產力工具。
可以看到,如今的英偉達已發展成為一家全棧式計算公司,無論是加速計算,還是計算機圖形,都通過在架構、設計和算法方面進行創新疊加來實現性能的突破。與此同時,AI技術已經滲透到英偉達產品的各個角落,用于與更多技術創新的結合,推動科學及工業領域更多AI新應用的突破,并為數字經濟發展提供動力。