進入2025年,國內車市智能化競爭進一步升級,一些車企開始喊出“全民智駕”的口號。而從技術層面來說,處在頭部位置的車企已經在推動下一代自動駕駛架構的落地。
在3月18日的NVIDIA GTC 2025上,理想汽車自動駕駛技術研發負責人賈鵬發表了主題為《VLA:邁向自動駕駛物理智能體的關鍵一步》的演講,并發布了理想汽車的下一代自動駕駛架構——MindVLA。

理想汽車董事長兼CEO李想當日在社交平臺發文稱,“MindVLA是一個視覺-語言-行為大模型,但我們更愿意將其稱為“機器人大模型”,它將空間智能、語言智能和行為智能統一在一個模型里,讓自動駕駛擁有感知、思考和適應環境的能力,是我們通往L4路上最重要的一步。”他還表示,MindVLA能為自動駕駛賦予類似人類的駕駛能力,就像iPhone 4重新定義了手機,MindVLA也將重新定義自動駕駛。
全棧自研,MindVLA開啟自動駕駛iPhone 4時刻
理想汽車的智能駕駛經過幾次迭代和升級。去年10月,理想汽車全量推送“端到端+VLM”雙系統方案后,該模式漸漸成為行業的標桿。許多企業開始采用這一路線。特別值得一提的是,不僅在自動駕駛領域,在通用機器人領域該系統也得到應用。
基于上述“端到端+VLM”雙系統架構的實踐,及對前沿技術的洞察,理想自研了MindVLA大模型。VLA是機器人大模型的新范式,其將賦予自動駕駛強大的3D空間理解能力、邏輯推理能力和行為生成能力。
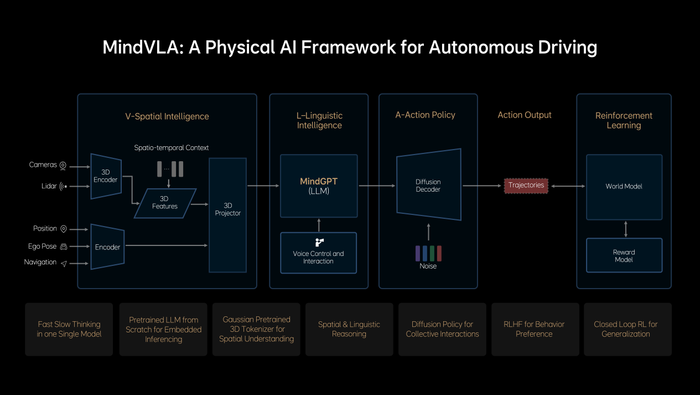
值得注意的是,MindVLA不是簡單地將端到端模型和VLM模型結合在一起,所有模塊都是全新設計。3D空間編碼器通過語言模型后,和邏輯推理結合在一起后,給出合理的駕駛決策,并輸出一組action token(動作詞元),action token指的是對周圍環境和自車駕駛行為的編碼,并通過diffusion(擴散模型)進一步優化出最佳的駕駛軌跡,整個推理過程都要發生在車端,并且要做到實時運行。
2010年中發布的iPhone 4是智能手機時代的首個爆款,也是智能手機滲透率加速提升的起點。對汽車行業來說,理想汽車最新的MindVLA也將重新定義自動駕駛,加速行業的快速發展。
從用戶體驗方面來看,有MindVLA賦能的汽車不再只是一個簡單的駕駛工具,而是一個能與用戶溝通、理解用戶意圖的智能體。能夠聽得懂、看得見、找得到,是一個真正意義上的司機Agent或者叫“專職司機”。

所謂“聽得懂”是用戶可以通過語音指令改變車輛的路線和行為,MindVLA能夠理解并執行“開太快了”“應該走左邊這條路”等這些指令。“看得見”是指MindVLA具備強大的通識能力,不僅能夠認識星巴克、肯德基等不同的商店招牌;當用戶在陌生地點找不到車輛時,可以拍一張附近環境的照片發送給車輛,擁有MindVLA賦能的車輛能夠搜尋照片中的位置,并自動找到用戶。“找得到”意味著車輛可以自主地在地庫、園區和公共道路上漫游,其中典型應用場景是用戶在商場地庫,可以跟車輛說:“去找個車位停好”,車輛就會利用強大的空間推理能力自主尋找車位,即便遇到死胡同,車輛也會自如地倒車,重新尋找合適的車位停下,整個過程不依賴地圖或導航信息,完全依賴MindVLA的空間理解和邏輯推理能力。
對于人工智能領域而言,汽車作為物理人工智能的最佳載體,未來探索出物理世界和數字世界結合的范式,將有望賦能多個行業協同發展。
打破傳統,六大關鍵技術引領行業創新
在理想交付端到端+VLM期間,空間智能、LLM、AIGC和具身智能等技術有了快速發展。基于此,理想開始思考能否將端到端模型和VLM模型合二為一,像GPT O1和DeepSeek R1一樣,讓模型自己學會快慢思考,同時賦予模型強大的3D空間理解能力和行為生成能力,將雙系統的天花板進一步打開。
MindVLA打破了自動駕駛技術框架設計的傳統模式,使用能夠承載豐富語義,且具備出色多粒度、多尺度3D幾何表達能力的3D高斯(3D Gaussian)這一優良的中間表征,充分利用海量數據進行自監督訓練,極大提升了下游任務性能。
而在過去,從單目2D特征到單目3D特征,再到多攝像頭的鳥瞰圖(BEV)特征和占據網格(OCC)等不同階段,大多依賴于監督學習,需要精準標注的數據,效率和數據利用率都很低下。
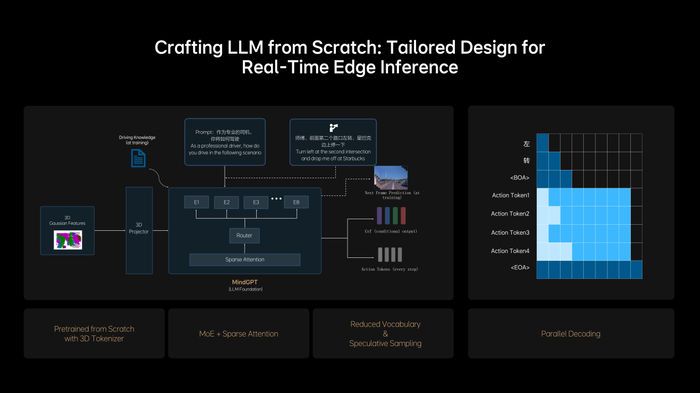
理想還從0設計和訓練一個適合VLA的LLM基座模型,使其具備3D空間理解和推理能力,并能在有限資源下實現實時推理,保證模型規模增長的同時,不降低端側的推理效率。而在訓練模型去學習人類的思考過程,理想讓快慢思考有機結合到同一模型中,并可實現自主切換快思考和慢思考。
為了把NVIDIA Drive AGX的性能發揮到極致,MindVLA采取小詞表結合投機推理,以及創新性地應用并行解碼技術,進一步提升了實時推理的速度。至此,MindVLA實現了模型參數規模與實時推理性能之間的平衡。
理想利用diffusion模型,將action token解碼成最終的駕駛軌跡,并讓RLHF與diffusion結合,學習和對齊人類行為的同時,提升安全下限。
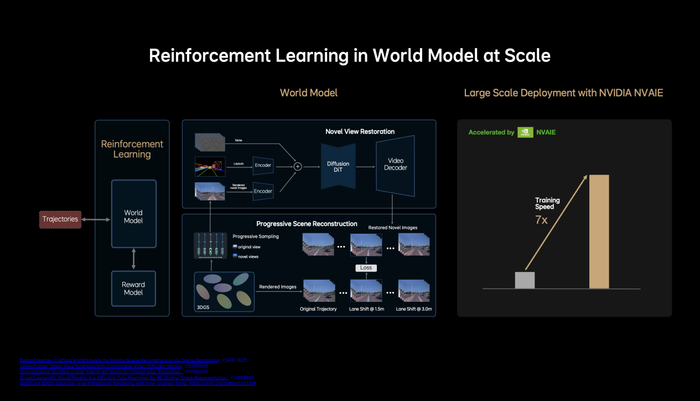
MindVLA基于自研的重建+生成云端統一世界模型,深度融合重建模型的三維場景還原能力與生成模型的新視角補全,以及未見視角預測能力,構建接近真實世界的仿真環境。源于世界模型的技術積累與充足計算資源的支撐,MindVLA實現了基于仿真環境的大規模閉環強化學習,即真正意義上的從“錯誤中學習”。過去一年,理想自動駕駛團隊完成了世界模型大量的工程優化,顯著提升了場景重建與生成的質量和效率,其中一項工作是將3D GS的訓練速度提升至7倍以上。
理想通過創新性的預訓練和后訓練方法,讓MindVLA實現了卓越的泛化能力和涌現特性,其不僅在駕駛場景下表現優異,在室內環境也展示出了一定的適應性和延展性。
持續精進,朝全球領先的AI企業再進一步
在上述六大技術的突破下,理想MindVLA能為自動駕駛行業帶來革命性的變化。而這離不開理想在智能駕駛技術、AI大模型等領域的持續投入。

理想在不斷進行技術創新的同時,還在人工智能領域頂級學術會議和期刊發表了大量論文,為加速技術發展貢獻了重要力量。
李想曾說過,理想要做的不是汽車的智能化,而是人工智能的汽車化,并將推動人工智能普惠到每一個家庭。從行業視角來看,汽車將從工業時代的交通工具,進化成為人工智能時代的空間機器人。在對整個世界的理解上,理想通過人工智能將物理世界與數字世界進行融合,讓有限的空間實現無限的延伸。