

界面新聞記者 | 李彪
界面新聞編輯 | 文姝琪
美國時間3月18日,英偉達在美國圣何塞舉辦GTC(GPU技術大會)。作為全球最受關注的科技巨頭,今年GTC吸引約2.5萬人線下參加,另有30萬人通過線上方式收看直播。
英偉達CEO黃仁勛在主題演講開場說道,“因為AI技術爆發,GTC大會的規模每年都在擴大。去年他們說GTC是AI行業的‘伍德斯托克搖滾音樂節’。今年我們搬進了體育場,GTC已經成AI行業的‘超級碗’”。
而在此次GTC大會上,英偉達不僅發布了Blackwell GPU、硅光交換機、機器人模型等一系列新產品。黃仁勛還在演講中反復傳遞出一個信號:隨著AI行業在模型訓練上的整體需求放緩,再加上DeepSeek在模型推理上所做創新,AI推理時代即將到來。
演講結束后,英偉達股價收盤跌超3.4%,報115.43美元/股,盤后繼續下跌0.56%。
Blackwell Ultra GPU:專為AI推理打造的“算力核彈”

作為GTC的重頭戲,黃仁勛在演講中宣布推出數據中心AI GPU的新一代產品——NVIDIA Blackwell Ultra GPU。
此前市場傳言英偉達去年年底計劃將Blackwell Ultra改名為B300 ,但根據現場公布的結果,官方保留了原始命名。Blackwell Ultra GPU相比于上一代B200GPU性能提升了50%,約為15P FLOPS(基于低精度的四位浮點數格式FP4標準),內存上則搭載了業內最先進的HBM3E,從192GB升級到了288GB。

基于Blackwell Ultra,英偉達面向云計算廠商等大型企業客戶客戶提供兩款系統集成產品:Blackwell Ultra NVL72機架式解決方案與NVIDIA HGX Blackwell Ultra NVL16系統。
其中,Blackwell Ultra NVL72是在一個數據中心機架(一臺服務器搭載8個GPU,一個機架可以容納多臺服務器)中連接了72個Blackwell Ultra GPU以及36個英偉達基于ARM架構設計的Grace CPU。據與上一代B200GPU的同類產品相比,Blackwell Ultra NVL72在AI算力性能上提升超過了50%。HGX Blackwell Ultra NV16則是運用NVLink高速互聯網絡連接8個Blackwell Ultra GPU的服務器系統產品。
與A100、H100等多款主要用在AI模型預訓練的產品不同,英偉達此次明確定位Blackwell Ultra“專為AI模型推理打造”(AI-Reasoning),同時兼顧"訓練和多場景AI應用的高效性"。Blackwell Ultra NVL72和HGX Blackwell Ultra NVL16(8GPU)兩款系統產品也在提升計算能力和內存容量的同時,專為復雜AI推理任務做了優化。以HGX Blackwell Ultra NVL16為例,相較于上一代Hopper架構,這款新品在大模型推理速度上提升了11倍。
此前在DeepSeek用極低的算力成本完成模型開發后,外界就曾擔憂市場對英偉達算力芯片產品的旺盛需求是否會放緩,英偉達官方及黃仁勛就曾在多個場合表示,相比于AI廠商先前將大量算力投資用于AI模型訓練上,DeepSeek主要在模型推理運用了創新技術,而AI推理依然需要大量英偉達GPU和高性能網絡。
在AI行業的“Scaling Law”法則(模型規模越大,模型越智能)在預訓練環節放緩后,推理環節將催生更大規模的算力需求,因此“DeepSeek的出現反而證明市場需要更多AI芯片”。
據黃仁勛介紹,Blackwell系列,目前已經全面投產。“產量驚人,客戶需求驚人,因為人工智能出現了一個拐點,由于推理人工智能以及推理人工智能系統和智能體系統的訓練,人工智能領域必須完成的計算量大大增加。”
按照英偉達“一年一更新”發布節奏,黃仁勛演講中預告了下一代Rubin架構兩款產品Rubin GPU、Rubin Ultra GPU的性能信息。
Rubin GPU算力性能將在FP4標準下達到50P Flops,約是Blackwell Ultra GPU的3.3倍,Rubin Ultra GPU則在相同標準下為100P。兩款新架構產品屆時也將用上HBM4、HBM4E先進AI內存。搭載Rubin GPU的Vera Rubin NVL144(連接144個GPU)將于 2026 年下半年推出,Rubin Ultra GPU的Rubin Ultra NVL576(連接576個GPU)將于2027年下半年推出。
繼Rubin架構之后,黃仁勛現場公布下一代GPU架構的命名為“Feynman”,取自著名物理學家理查德?費曼(Richard Feynman),Feynman架構產品將于2028年發布。
智能體和機器人時代,AI將需要更多芯片
與去年GTC密集發布各種新產品的節奏不同,黃仁勛今年在公布新品前,在現場花了更多時間科普“Agentic AI”的概念,以及AI推理帶來的巨大改變。
在現場展示的AI技術發展路線圖中,黃仁勛按照“Generative AI(生成式AI)、Agentic AI(智能體)、Physical AI(具身AI)”三個階段的進化路線,將Agentic AI描述為AI技術發展的中間態。
相比于生成式AI的主要應用——語言大模型與聊天機器人——主要聚焦于生成文本、圖像內容,Agentic AI更進一步,能夠理解任務、進行復雜推理、制定計劃并自主執行多步驟操作,目前業內熱議的數字員工等AI Agent即為相關應用。
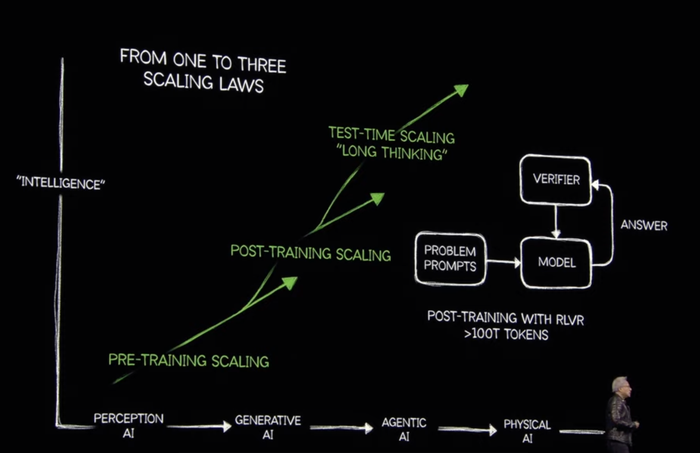
在生成式AI的第一階段,AI行業的“Scaling Law”法則集中體現在模型訓練上,特別是預訓練環節(Pre-Training,即從無到有開發模型的前期訓練階段),投入更多的數據、更大規模的算力資源訓練出更好的模型,訓練規模越大,模型越智能。
黃仁勛認為,從過去一年的行業發展進程來看,預訓練為主的Scaling Law法則已走入“誤區”。從今年乃至未來很長一段時間內,Agentic AI將代替生成式AI,成為行業新的發展方向。由于Agentic AI強調自主性與復雜問題解決能力,每一步解決復雜問題、分解任務的邏輯思考過程都需要用到“模型推理”,因此推理將成為新階段的核心動力。
而從生成式AI發展到Agentic AI,并不意味著Scaling Law法則失效。相反,由于將應用范圍從訓練進一步擴展到推理,不只在預訓練環節,模型的后訓練(Post-Training,指預訓練得到模型后,根據特定任務或需求,使用更小規模、更專注的數據集對模型進行進一步優化訓練或微調的過程)和日常推理的長期思考(Long-Thinking)都要繼續消耗算力資源,Scaling Law法則對規模的要求非但會變小,相反會進一步擴大。
以一個用戶訪問AI應用時產生的Token來舉例,對于Agentic AI來說,推理所涉及的任務更加復雜,可能需要生成或處理更多Token來完成規劃和執行。同時隨著更多用戶同時訪問AI,Token的數量會爆炸式增加。對于大模型來說,每生成一個Token往往需要數千億次浮點運算,如何在有限時間內盡可能多的生成Token,并快速將推理結果反饋給用戶,大規模的算力資源是完成這一切的基礎。
按照現場顯示的效果,Blackwell Ultra NVL72集群在運行DeepSeek-R1 671B交互式副本時,只需10秒就可以給出答案,而上一代Hopper架構的H100同類產品則需要1分半。
此次大會上,英偉達還發布了一款新型的AI 推理服務軟件Dynamo。它協調和加速數千個GPU之間的推理通信,并使用分解服務將大型語言模型的處理和生成階段分離在不同GPU上。這允許每個階段根據其特定需求進行獨立優化,并確保最大程度地利用GPU資源。
黃仁勛認為,推理所需算力需求規模增長能“輕松超過去年估計的100倍”,未來行業需要更多、性能更強的AI芯片。根據他的預測,數據中心建設的投入到2028年將達到1萬億美元,目前“相當確定很快就會達到這個目標”。
硅光網絡交換機、機器人模型與量子計算研究中心
此外,在今年GTC大會上,英偉達還將在硅光芯片、機器人應用、量子計算等領域有進一步的探索。
硅光領域,英偉達最新發布了NVIDIA Spectrum-X(基于以太網,適合兼容更廣泛的企業網絡)及NVIDIA Quantum-X(基于InfiniBand,偏向專用計算集群)硅光網絡交換機。
這兩款硅光網絡交換機新品是英偉達首次利用“光電共封裝技術”(co-packaged optics, CPO)將光通信直接集成到交換機上,推出的商用化硅光交換機產品。此前英偉達的交換機產品的光通信部分主要為“外掛式”,依賴從Finisar和Lumentum等外部供應商采購的標準化模塊。
此次英偉達的硅光網絡交換機新品與臺積電、Coherent、康寧公司(Corning)、富士康、Lumentum和SENKO等行業巨頭合作。Quantum-X交換機預計將于今年晚些時候上市,Spectrum-X交換機預計于2026年通過主流基礎設施和系統供應商推出。
黃仁勛曾經用“A工廠”描繪AI時代超大規模數據中心的未來形態。隨著AI數據工廠規模的擴張,網絡基礎設施也需要同步徹底革新。英偉達希望通過將硅光子技術直接集成到交換機中,突破超大規模和企業網絡的傳統限制,為目前萬張、十萬張GPU的數據中心向百萬張GPU的AI工廠過渡奠定基礎。
機器人作為未來“具身AI”(Physical AI)的關鍵應用,英偉達旗下輔助生成機器人訓練數據的物理世界模型Cosmos、人形機器人基礎模型GROOT N1以及3D實時仿真平臺Omniverse是這一領域的主要產品。

其中,GROOT N1是通用機器人基礎模型,英偉達此次正式宣布已經將其開源。GROOT N1模型采用雙系統架構,靈感來自人類認知原理。在視覺語言模型的支持下,一個系統可以推理其環境和收到的指令,從而規劃行動。另一個系統然后將這些計劃轉化為精確、連續的機器人動作。
除硅光芯片與機器人應用外,在谷歌、微軟相繼在量子計算芯片領域有重大突破后,量子計算當前成為了硅谷科技巨頭布局未來的一個熱門方向。英偉達此次也在GTC大會上宣布,將在波士頓建設NVIDIA加速量子研究中心(NVAQC)。據官方介紹,該中心是一個以研究為導向的機構,將通過尖端技術推動量子計算架構與算法的發展。
值得關注的是,去年谷歌發布的Willow芯片攻克困擾量子計算研究30年的“量子糾錯”難題,市場升溫帶動量子計算概念股上股價漲,黃仁勛曾在今年1月接受分析師采訪時給量子計算的落地“潑了一盆冷水”:要造出“非常有用的量子計算機”,可能需要20年。黃的這一評價當時導致一眾量子計算相關股票應聲下跌。
黃仁勛在談及英偉達成立量子研究中心的目標時提到,量子計算的實用化依賴于解決關鍵技術挑戰,如量子比特噪聲和糾錯。而NVAQC的使命是推動這些突破:“NVIDIA加速量子研究中心將是突破發生的地方,以創建大規模、有用的加速量子超級計算機。”
對于市場擔憂量子計算顛覆現有計算工具,以前所未有的計算速度在密碼學、隱私數據保護領域形成“量子霸權”,黃仁勛明確表示,量子計算不會單獨取代現有的計算技術,而是作為AI計算能力的補充。未來的量子計算將成為AI超級計算機的“增強工具”,在藥物開發、新材料制造等特定高復雜性領域發揮作用。