
文 | 奇點(diǎn)湃
繼2023年美國的OpenAI向全球AI界,投了一顆深水炸彈——ChatGPT后,2025年,誕生于中國杭州的DeepSeek,再次掀起了巨浪。
簡單來說,DeepSeek脫穎而出,是其以極低的成本實(shí)現(xiàn)了和GPT系列一樣的效果——DeepSeek研究人員表示,開發(fā)該應(yīng)用程式僅花費(fèi)600萬美元(480萬英鎊),遠(yuǎn)低于美國AI公司花費(fèi)的數(shù)十億美元。
而兩個大模型的推出,都把國內(nèi)的AI大廠們推到風(fēng)口浪尖。第一次大廠們的一致回應(yīng)是,我們也有,待會就發(fā)。而此刻,面對國產(chǎn)AI中小廠跑出的Deepseek,大廠做出了截然不同的反應(yīng):
騰訊早早給出了一個全面擁抱DeepSeek的姿態(tài):從2月8日開始,據(jù)不完全統(tǒng)計(jì),已經(jīng)接入了騰訊云、微信、騰訊游戲等14個自家生態(tài);字節(jié)與阿里態(tài)度一致,現(xiàn)已接入部分生態(tài),但豆包AI助手和通義大模型不接入。
而相比之下,百度卻略顯“擰巴”:在2月12日百度智能云事業(yè)群(ACG)全員會上,現(xiàn)任百度智能云事業(yè)群總裁沈抖表示,DeepSeek在短期內(nèi)會對百度產(chǎn)生影響,但長期來看是利大于弊的。
而兩天之后,百度一改先前一直堅(jiān)持的閉源路線,毫無預(yù)兆地對外宣布,公司將在未來幾個月陸續(xù)推出文心大模型 4.5 系列,并于 6 月 30 日起正式開源。
又是2天過去,百度搜索宣布將全面接入DeepSeek和文心大模型最新的深度搜索功能。緊接著,百度文心智能體平臺宣布已全面接入DeepSeek模型,全部免費(fèi)。
一番操作的背后邏輯是——百度短期承認(rèn)deepseek的能力,同時(shí)將其接入自己的智能體平臺之中,甚至在這一節(jié)點(diǎn)推翻了一直以來堅(jiān)持的閉源路線。長期來看,由于大模型考察的點(diǎn)還有很多,Deepseek反而會推動百度的發(fā)展。
而百度的“擰巴”背后,是對現(xiàn)階段業(yè)績,AI大模型商業(yè)化情況的深深焦慮。
01 沈抖與譚待之爭,解開了百度的焦慮
自百度成為百模大戰(zhàn)發(fā)起者以來,引發(fā)了不少行業(yè)內(nèi)的激烈討論。
據(jù)光子星球報(bào)道,在2月12日百度智能云事業(yè)群全員會上,沈抖表示:“國內(nèi)大模型去年‘惡意’的價(jià)格戰(zhàn),導(dǎo)致行業(yè)整體的創(chuàng)收相較于國外差了多個數(shù)量級”,緊接著便把字節(jié)的豆包單獨(dú)拎出來舉了例子——其訓(xùn)練成本和投流成本都很高。
很快,火山引擎總裁譚待便在朋友圈用數(shù)據(jù)反擊了“惡意”二字——豆包1.5Pro模型的預(yù)訓(xùn)練成本、推理成本均低于DeepSeek V3,更是遠(yuǎn)低于國內(nèi)其他模型,在當(dāng)前的價(jià)格下有非常不錯的毛利。
簡單來說,豆包的降價(jià)并非是惡意搞價(jià)格戰(zhàn),而是由于技術(shù)進(jìn)步實(shí)現(xiàn)了低價(jià)。譚待表示,“國內(nèi)外的廠商都在依靠技術(shù)創(chuàng)新,降低模型價(jià)格。我們也只是實(shí)現(xiàn)了Gemini 2.0 Flash的價(jià)格水平而已,這個價(jià)格完全是依賴技術(shù)進(jìn)步做到。”
那么,百度為何單把豆包拎出來?
“投流成本”四字仿佛給了我們答案——豆包擁有抖音這個億級DAU的“優(yōu)先宣傳權(quán)”,這就導(dǎo)致,其C端數(shù)據(jù)非常好看。據(jù)量子位數(shù)據(jù),豆包APP在2024年11月平均每天有80萬新用戶下載豆包,DAU(日活躍用戶數(shù)量)接近900萬,增長率超過15%,在國內(nèi)超第二名Kimi DAU的300萬。
在B端都沒有成熟的時(shí)候,C端高活躍量似乎成了大家對大模型表現(xiàn)的評判標(biāo)準(zhǔn)——既能展現(xiàn)其能力不錯,還能體現(xiàn)其潛在能力的提高空間——用戶還可以通過即時(shí)反饋答案質(zhì)量,免費(fèi)幫字節(jié)訓(xùn)練豆包,提高“智力”。
而當(dāng)外界并非把商業(yè)化表現(xiàn)作為AI廠商能力的主要衡量因素時(shí),沈抖的話里話外卻展露了急于拿出商業(yè)化數(shù)據(jù)的心態(tài)——“惡意”的價(jià)格戰(zhàn),“行業(yè)整體的創(chuàng)收相較于國外差了多個數(shù)量級”。
急于商業(yè)化的原因,或許能從一組數(shù)據(jù)看出。
2月18日,百度發(fā)布2024年第四季度及全年財(cái)報(bào),財(cái)報(bào)顯示,2024年總收入為1331億元,同比減少1%。百度核心收入為1047億元,同比增長1%;在線營銷收入為730億元,同比減少3%,及非在線營銷收入317億元,同比增長12%,主要由智能云業(yè)務(wù)帶動。
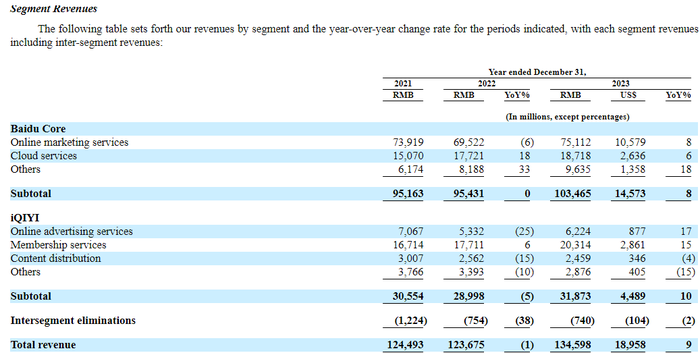
(百度財(cái)報(bào) 圖源:百度)
而在2023財(cái)報(bào)之中,2021-2023云服務(wù)與其他收入(包括阿波羅自動駕駛,小度智能硬件)是分開算的。而根據(jù)同花順財(cái)經(jīng)數(shù)據(jù),百度云服務(wù)2021-2023收入增速分別是64%,18%,6%,而其他收入分別是91.26%,33%,18%。也就是說,2024主要由智能云業(yè)務(wù)帶動的非在線營銷收入,增速仍有可能主要由其他業(yè)務(wù)貢獻(xiàn)。
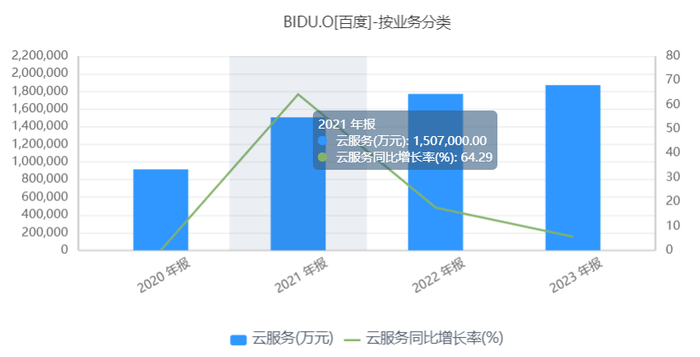
(百度云服務(wù)收入及增速 圖源:同花順財(cái)經(jīng))
作為基本盤的核心業(yè)務(wù)下滑,云服務(wù)收入增速放緩,是百度現(xiàn)如今焦慮的根源,基于此,有以上“擰巴”的表達(dá)。
02 李彥宏推翻自己,百度的技術(shù)落后了嗎?
而上次如此激烈的討論,還是關(guān)于閉源與開源路線的選擇。
在今年以前,對于其選擇的閉源路線,百度的態(tài)度十分堅(jiān)定。去年4月,李彥宏曾提出“開源模型會越來越落后”。隨后不久,360集團(tuán)董事長周鴻祎在公開場合發(fā)出反對聲音稱,如果沒有開源文化,就不會有Linux、PHP、MySQL等眾多重要的技術(shù)成果,甚至互聯(lián)網(wǎng)的發(fā)展也會受到極大的限制。
對此,李彥宏進(jìn)一步給出了依據(jù)——如果開源模型想要在能力上追平閉源模型,就需要更大的參數(shù)規(guī)模,這將導(dǎo)致更高的推理成本和更慢的反應(yīng)速度。同時(shí),相比源代碼公開傳統(tǒng)的軟件開源,大模型的開源更為復(fù)雜。
3個月過去,2024世界人工智能大會(WAIC 2024)期間,李彥宏更是直接“開炮”:開源模型是智商稅。 而隨后8月份,百川智能CEO王小川闡述了二者的關(guān)系。他預(yù)計(jì),未來80%的企業(yè)會用到開源大模型,因?yàn)殚]源沒辦法對產(chǎn)品做更好的適配,或者成本特別高。而閉源可以給剩下的20%提供服務(wù)。二者不是競爭關(guān)系,而是在不同產(chǎn)品中互補(bǔ)的關(guān)系。
總的來說就是,開源閉源皆是行業(yè)所需,并非零和博弈。實(shí)際上,路線之爭的背后往往是商業(yè)路線的分歧。
開源大模型的核心理念是開放源代碼,允許公眾訪問、使用、修改和分發(fā)模型的源代碼。面對市場競爭,開源大模型的免費(fèi)使用是非常有吸引力的獲客手段;同時(shí),低成本的試錯也有助于開源大模型更快觸達(dá)潛在用戶群體,降低企業(yè)認(rèn)知和決策難度,加速創(chuàng)新。
而閉源大模型服務(wù)能力更強(qiáng),商業(yè)化走得更快。華泰證券指出,產(chǎn)業(yè)化方面,閉源大模型的長期服務(wù)能力更強(qiáng)、更可用。大模型與業(yè)務(wù)結(jié)合,需要產(chǎn)品、運(yùn)營、測試工程師等多種角色共同參與,同時(shí)大模型的長期應(yīng)用所需的算力、存儲、網(wǎng)絡(luò)等配套都要跟上,開源社區(qū)無法幫助用戶“一站式”解決這些細(xì)節(jié)問題。
堅(jiān)持閉源路線的百度,想通過更強(qiáng)的服務(wù)能力從而保持用戶粘性,為其云業(yè)務(wù)以及其他相關(guān)業(yè)務(wù)帶來增量,這是人之常情。而華泰證券指出,盡管閉源大模型整體能力更強(qiáng),OpenAI的GPT-4、Anthropic的Claude-3、谷歌的Gemini Ultra都是閉源。
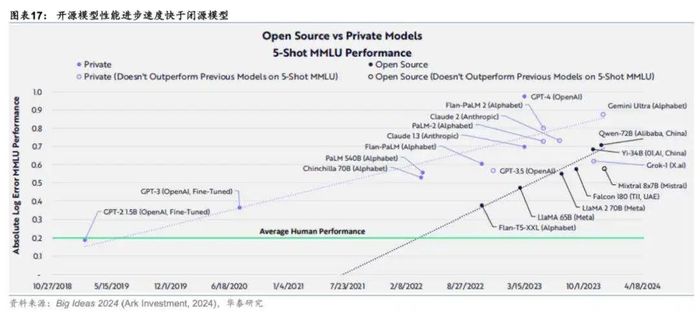
(開源模型性能進(jìn)步速度快于閉源模型 圖源:華泰證券)
開源陣營的日漸壯大,確實(shí)給閉源模型帶來了一定沖擊。
今年1月31日,OpenAI首席執(zhí)行官Sam Altman發(fā)表了以下言論:我個人認(rèn)為,我們站在了歷史錯誤的一邊,需要制定不同的開源策略。緊接著半個月不到,OpenAI也開始考慮開源路線。
2月13日,Altman發(fā)布消息稱,GPT-4.5、GPT-5即將陸續(xù)發(fā)布,免費(fèi)版ChatGPT將在標(biāo)準(zhǔn)智能設(shè)置下無限制使用GPT-5進(jìn)行對話。此外,他還特別指出,OpenAI的新路線是:跨越o3、免費(fèi)訪問、開源“模型規(guī)范”。
此刻,我們能夠發(fā)現(xiàn),百度從一開始便是想要通過閉源大模型快速商業(yè)化,鞏固百模大戰(zhàn)第一人的位置。而在B端商業(yè)化路徑還不明晰的時(shí)候,開源大模型又涌現(xiàn)出了deepseek,再加上ChatGPT也在試圖兩條腿走路,百度如果想要保持現(xiàn)有身位,就算是打臉,也要去交開源的智商稅。
于是,2月18日,在百度2024年第四季度及全年財(cái)報(bào)電話會上,李彥宏表示:開源的決策源自對技術(shù)領(lǐng)先地位的堅(jiān)定信心,開源將進(jìn)一步促進(jìn)文心大模型的廣泛應(yīng)用,并在更多場景中擴(kuò)大其影響力。
03 百度,最終會被“蘋果們”放棄嗎?
可以預(yù)見的是,開源與閉源共存是今后廠商們的選擇。那么,在百度堅(jiān)持閉源大模型的這幾年里,B端開拓情況如何?
我們都知道的是,在文心一言還沒發(fā)布之時(shí),就有許多廠商搶著發(fā)布接入文心一言的合作訊息,就如這段時(shí)間的deepseek一樣。而上述財(cái)報(bào)數(shù)據(jù)顯示,文心一言所在的百度智能云板塊收入的增速放緩,這也暗示著應(yīng)用層的廠商們從AI熱中冷靜下來,去思考目前的AI是否真的為企業(yè)帶來了價(jià)值。
而能讓應(yīng)用層廠商再次下單的,一定是能夠帶來實(shí)際效果的AI解決方案,無論是底座還是落地服務(wù),都需要更智能的技術(shù)。
在全球科技大廠的對外宣傳語境里,投入資源的數(shù)量,依然是衡量人工智能模型的智能程度的一個標(biāo)準(zhǔn)。
數(shù)據(jù)顯示,亞馬遜、谷歌、微軟和 Meta在 2025 年的資本支出將超過 3200 億美元,其中 Meta 今年的資本支出將達(dá)到 600 億至 650 億美元,較 2024 年的 392.3 億美元大幅增加,一個重要的原因還是押注人工智能。
阿里同樣把資本性支出當(dāng)做宣傳點(diǎn)——2024Q4,阿里巴巴在該季度資本開支大幅增長至317.75億元,環(huán)比大增80%,阿里巴巴明確表示,這主要由于公司對云基礎(chǔ)設(shè)施的投入增加。
騰訊2024Q3實(shí)現(xiàn)資本開支171億元,同比增長114%。
阿里和騰訊,都在2024對算力資源和 AI 基礎(chǔ)設(shè)施進(jìn)行大規(guī)模的投入。反觀百度,隨著營業(yè)收入增速下滑,資本支出上也顯得更為謹(jǐn)慎。可以看到,百度(除愛奇藝)資本性支出2023年,2024年分別是111億元與81億元。
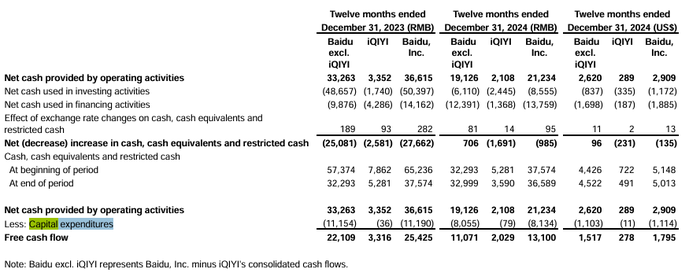
(百度財(cái)報(bào) 圖源:百度)
而百度和阿里在資本支出上的差距,或許是蘋果在國內(nèi)找了兩家AI公司進(jìn)行國產(chǎn)iPhone AI功能落地的原因之一。
去年12月,蘋果公司宣布與百度達(dá)成合作協(xié)議,雙方將攜手于2025年在中國推出一項(xiàng)名為Apple Intelligence的生成式人工智能服務(wù)。此次合作不僅限于在蘋果設(shè)備上部署小型模型,雙方還將在云端運(yùn)行大型模型,以提升整體AI服務(wù)能力。Siri也將整合百度的人工智能模型,期望通過這一合作帶來更加精準(zhǔn)的搜索結(jié)果和用戶體驗(yàn)。而就在2月14日,阿里官方已經(jīng)確認(rèn)目前正在與蘋果合作,針對中國市場進(jìn)行本地化AI接入。
盡管蘋果選擇阿里,還有一個原因是希望通過多個合作伙伴來降低風(fēng)險(xiǎn),但百度資本性支出較低是不爭的事實(shí)。
目前百度能做的,是實(shí)打?qū)嵉募哟驛I投入,同時(shí)給出一份文心大模型的成功落地范例。百度也是如此規(guī)劃的——財(cái)報(bào)會上,李彥宏表示基礎(chǔ)模型只有在大規(guī)模解決現(xiàn)實(shí)問題時(shí),才具備真實(shí)價(jià)值。
簡單來說就是,百度將繼續(xù)卷應(yīng)用。而在財(cái)報(bào)會上,多次提到了“搜索”二字:
當(dāng)前,約有22%的搜索結(jié)果頁面包含了AI生成的內(nèi)容
對我們而言,關(guān)鍵是保持快速而堅(jiān)定的AI轉(zhuǎn)型步伐,專注于發(fā)現(xiàn)用戶真正需要和想要的下一代搜索體驗(yàn)。
百度將繼續(xù)投資于推進(jìn)百度AI能力,這是長期的戰(zhàn)略優(yōu)先事項(xiàng)。基于這一點(diǎn),百度將進(jìn)一步深化AI轉(zhuǎn)型,特別是在搜索產(chǎn)品的領(lǐng)域。
如此看來,百度的殺手級應(yīng)用,還是在搜索業(yè)務(wù)上,想既為自己的老本行提供新動力,也想把AI的戰(zhàn)績刷一刷。
值得一提的是,字節(jié)和阿里都沒有在核心產(chǎn)品接入Deepseek,百度卻在文心模型和搜索等核心平臺和產(chǎn)品上都接入了Deepseek。
于是,短期來看,百度需要與deepseek進(jìn)行進(jìn)一步的合作。
一是為了更好地把搜索業(yè)務(wù)變得更加智能,讓文心智能平臺用戶也能嘗鮮享受服務(wù)。二也能借機(jī)銷售一波云服務(wù)。沈抖表示,短期內(nèi)DeepSeek的組織和商業(yè)化還需要時(shí)間去完善。在這個窗口期,整個市場被教育后,所產(chǎn)生的未被滿足的需求,云廠商還有承接的機(jī)會。
簡單來說就是,成為deepseek未來的合作商——目前deepseek依靠自建的數(shù)據(jù)中心,出現(xiàn)了服務(wù)器崩潰問題,云廠商能通過提供服務(wù)成為其后盾。但目前為止,DeepSeek在任何層面都沒有跟云廠商芯片廠商開啟合作,雖然春節(jié)期間云廠商紛紛宣布讓DeepSeek模型跑在其云上,但他們并沒有開展任何真正意義的合作。
而長期來看,正如譚待所進(jìn)一步呼吁的,包括百度在內(nèi)的AI廠商,應(yīng)該像 DeepSeek 一樣聚焦基本功,聚焦創(chuàng)新,不急不躁,少無端猜測,歸因外部。
百度發(fā)布大模型以來,其發(fā)表的部分言論較為偏激,釋放著焦慮的信號。而現(xiàn)如今,百度需要摒棄外部與內(nèi)部的噪音,潛心做研發(fā),如此,老本行搜索能煥發(fā)新機(jī),大模型商業(yè)化之路也會越來越清晰。