

2月14日早10點,百度官方微信發布公告,用短短一句話宣布放棄堅持了兩年的閉源之路,轉身站到自己曾不以為然的反面。公告寫道:
“我們將在未來幾個月中陸續推出文心大模型4.5系列,并于6月30日起正式開源。”
從2023年3月16日文心一言啟動邀測至今的約兩年時間里,百度創始人李彥宏始終站在“大模型閉源”的一端,在多個公開場合表達自己“開源會越來越落后”“開源就是智商稅”的理念。

李彥宏于2024百度世界大會,圖源/百度 「電廠」查閱公開資料發現,最晚在2024年下半年的一次百度內部講話中,李彥宏還公開重申了自己對閉源的堅持,“效率上開源模型是不行的”,閉源模型才是“商業模型”。
在百度堅持閉源的時間里,李彥宏的觀點也曾引起多番業界討論,如360創始人周鴻祎就公開嗆聲。在2024年4月舉辦的第二十七屆哈佛中國論壇上,周鴻祎曾講道:“我是一直相信開源的力量,至于說網上有些名人胡說八道,你們別被忽悠了。他說開源不如閉源好?連說這話的公司自己都是借助了開源的力量才成長到今天。”
沒人能預料到,短短幾個月后,百度和李彥宏悄然調轉了船頭,這場曾在國內AI市場持續的口水戰也有了階段性答案。而這種轉變很難說是出于主動還是被動。


DeepSeek技驚四座,百度被動防御?
2024年12月26日、2025年1月20日,由創企深度求索開發的DeepSeek-V3、DeepSeek模型分別上線并開源。兩款模型在性能與成本方面都達到了全球領先水平,因此一經亮相,就吸引了AI圈乃至整個用戶市場的注意力。
與此同時,面向普通C端用戶的DeepSeek App也迎來了破天流量,1月27日,DeepSeek的下載量在中外蘋果App Store免費榜登頂。另據QuestMobile統計,1月28日,DeepSeek App日活超越字節跳動旗下豆包,成為國內日活用戶最多的大模型對話產品;2月1日,其日活突破3000萬大關,成為了市場最快達到這一里程碑的應用。凡此種種,引來了行業的關注與忌憚。
比如,當地時間1月31日,OpenAI創始人Sam Altman首次提及了對閉源模式的反思,作為一家從GPT3開始堅持模型閉源的公司,稱“我們可能站在了歷史錯誤的一邊”;OpenAI首席研究官Mark Chen也承認DeepSeek在獨立研究的情況下發現了一些OpenAI o1 的核心idea,但同時指出外部反應是夸大的,OpenAI未來將在成本與性能兩端持續優化。
另一家AI大模型領軍企業,同樣堅持閉源的Claude大模型母公司Athotipic的CEO則于1月底發布萬字長文,分析了DeepSeek帶來的影響,認為DeepSeek威脅了美國在AI界領導地位的說法是夸大的。
然而,不同于海外大模型巨頭等企業在第一時間就對DeepSeek表態及強調自己仍有競爭力,包括百度在內的國內大模型玩家則沉默了許多。直到近日,百度才開始做出反應。
在2月11日開幕的2025迪拜世界政府高峰峰會上,李彥宏開始側面回應DeepSeek的爆火,他講道:“我們到處都能看到創新,我們必須適應這種快速變化的創新。”
同一天,百度宣布文小言App(原“文心一言”) 更新4.9.0版本,并接入DeepSeek R1模型。
2月12日,百度智能云事業群總裁沈抖在事業群全員會上提到:“每當科技的發展走到瓶頸期,總會有一個引領性的組織制造出拐點,而DeepSeek就是這個拐點。”他認為DeepSeek會促進開發生態會進一步繁榮,肯定了DeepSeek帶來的影響。
2月13日,百度官宣文心一言將從4月1日起全面免費,允許PC端與App端用戶體驗文心系列最新模型。
不過百度并未提及接下來面向企業客戶與開發者的Token收費規則是否變化,「電廠」就此詢問百度官方,截至發稿暫無回復。
2月14日,百度最終官宣了計劃為文心大模型新版本開源的消息。

百度開源能做到什么程度?
DeepSeek的官網中寫有這樣一句話:“‘以開源精神和長期主義追求普惠 AGI’是DeepSeek一直以來的堅定信念。”
而這一點正與百度過往嘗試走通的大模型之路相悖。但在不到一個月的時間里,DeepSeek迅猛增長、甚至被稱為展現了AGI的曙光之時,所有人都不得不停下來重新思考開閉源之間的選擇,以及重新檢視過往兩年的大模型研發范式。
而在公眾眼里,百度則在短短數天之內,以一種戲劇化的方式倒向了自己的反面。
不過,百度并沒有給出有關文心一言開源的更多細致信息。曾就職于一家大模型公司的Lily(化名)告訴「電廠」:“目前開源社區中的中文大模型多數并非是完全可商用,一般開源社區用戶通常需要進行復雜的商用授權申請流程,在某些情況,甚至有對公司規模、所在行業、用戶數等維度有明確規定不給予商業授權。”
而現有的開源協議繁多,較為常見的有GPL、LGPL、BSD、Apache、Mozilla、MIT等,對于是否包含源代碼、是否允許商業使用、是否授權轉售等規定不盡相同。
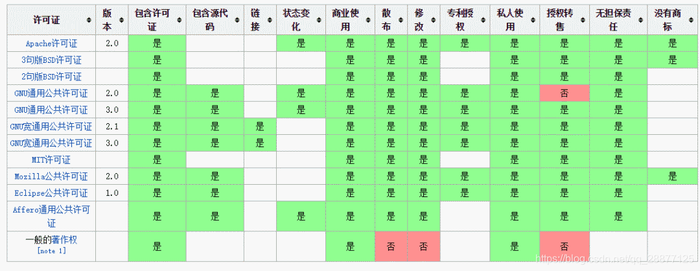
常見開源協議,圖源/CSDN GitCode開源社區 根據官方信息,DeepSeek-V3及R1模型均采用MIT協議開源,這是一種較為寬松的開源協議,意味著任何人都可以自由使用該模型,用于包括商業用途并進行模型蒸餾,無需申請。
(注:模型蒸餾是一種模型壓縮技術,可以將大型模型中的知識轉移到小型模型中。)
正因如此,DeepSeek堪稱最為強大和開放的開源模型之一。作為對比,Meta旗下Llama系列模型并未采取公開的開源協議,而是定制了許可協議。
其中Llama 1在發布時僅許可了研究用途;Llama 2支持產品活躍用戶小于7億的商業使用(如果超過7億需另向Meta進行申請);Llama 3.2系列模型的許可證中則寫道“任何居住在歐盟的個人或在歐盟有主要營業地點的公司不被授予使用 Llama 3.2 中包含的多模態模型的許可權”。
而百度的大模型開源能夠做到什么程度,是否能夠刺激到足夠數目的開發者共建生態,或許要到其新模型發布的那一天才有答案。
