
文|IT時報記者 毛宇
編輯|郝俊慧 孫妍
DeepSeek的“鯰魚效應”正在加速。
2月13日,文心一言宣布,4月1日起全面免費,同時上線深度搜索功能。此前,百度基于文心一言 4.0 Turbo推出的專業版會員服務定價為59.9元/月。

同日,OpenAI宣布GPT-4.5和GPT-5路線圖更新、模型規范重大更新,并預告GPT-4.5和GPT-5將在幾周/幾個月內推出,更重要的是,ChatGPT的免費套餐將在標準智能設置下獲得對GPT-5的無限制聊天訪問權限。
不過,對于業內更為關注的API(應用程序編程接口)服務費用,百度和OpenAI卻沒有給出更多信息,當C端用戶可以免費獲得越來越好的AI服務時,開發者們更希望大模型的算力價格戰來得更猛烈些。
2月9日,DeepSeek-V3宣布,結束API服務45天優惠期,價格回調至原價,輸入每百萬Token收費0.5元(緩存命中)至2元(緩存未命中),輸出價格則定為每百萬Token 8元,是優惠期的4倍。
不過,在業內人士看來,這個價格“仍然是高性價比”,盡管從2024年5月開始,國內各大模型廠商先后展開多輪價格戰,但在開發者看來,只是“噱頭更足”,因為性能強大的高階模型“還是很貴”,DeepSeek的算法架構創新和分布式訓練優化等創新,才真正將價格打下來。
新一輪的大模型價格戰,箭在弦上。有分析指出,這場由算法突破驅動的價格革命,可能重塑全球AI服務市場格局,加速市場洗牌進程。
價格更為敏感的算力市場已暗流涌動,山海引擎COO彭璐告訴《IT時報》記者,國內企業都已經在加快提升國產算力部署規模。不過,基于“DeepSeek的低成本能力,預計數據中心的算力價格不會上漲”。
創新誕生“AI界拼多多”
DeepSeek被稱為“AI界的拼多多”是有道理的。
目前,OpenAI GPT-4o API服務定價為每百萬輸入Token 1.25美元(緩存命中)(約9.13元人民幣)/ 2.5美元(緩存未命中)(約18.27元人民幣),每百萬輸出Token 10美元(約73.091元人民幣),而Claude 3.5-Sonnet依然是最昂貴的模型,價格高出DeepSeek-V3數倍。
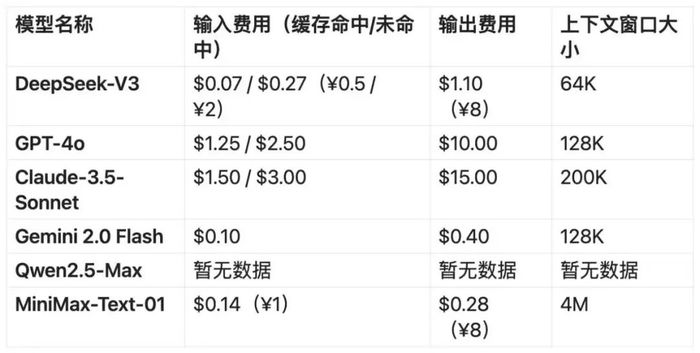
即便是DeepSeek推理能力更強、性能比肩OpenAI o1正式版的R1模型,每百萬輸入Token 1元(緩存命中)/4元(緩存未命中),每百萬輸出Token 16元的API服務價格,也幾乎是OpenAI o1同等規模輸入15美元(約109元人民幣)和輸出60美元(約437元人民幣)的二十分之一到百分之一。
國內大模型企業從2024年5月進入降價周期,通義、豆包、Kimi、百度的降幅大多在80%以上,但當去年12月DeepSeek發布V3時,尤其是在45天優惠期內,價格非常香。
“DeepSeek的低價源自成本夠低。”上述AI業內人士表示,DeepSeek采用的MOE模型架構并不很新,MiniMax等國內廠商也早已開始應用,但DeepSeek-V3引入了多頭潛在注意力機制,通過低秩壓縮技術減少了推理時的Key-Value緩存,顯著提升了推理效率,此外,DeepSeek-R1在做訓練時,跳過了傳統訓練中的監督微調(SFT)步驟,使用了RL強化學習的方法,完全依賴環境反饋來優化模型行為,同樣省去很多算力成本。
大模型算力價格有望普降
沒讓大家失望,“AI界拼多多”果然將價格打下來了。由于DeepSeek完全采用開源模式,這些技術創新正在被全球人工智能產業學習并復刻,大模型算力價格有望迎來一次普降。
短短一個多月過去,DeepSeek橫空出世帶來的“鯰魚效應”明顯。據《IT時報》記者觀察,截至目前,已有多家國產大模型廠商推出新的性能比肩DeepSeek-V3的產品,加上優惠期結束,V3已不是絕對的“性價比之王”。
同樣走開源路線的阿里云大模型通義,在2月4日三方基準測試平臺ChatbotArena公布的最新大模型盲測榜單上,以剛剛發布的Qwen2.5-Max超越DeepSeek V3、o1-mini和Claude-3.5-Sonnet等模型,成為非推理類的中國大模型冠軍。目前Qwen2.5-Max的API調用價格還未公布,而在2024年9月發布的價格表上,通義的上一代旗艦模型、性能逼近 GPT-4o的Qwen-Max每百萬Token輸入成本為2.4元,輸出成本為每百萬Token9.6元,略高于DeepSeek-V3。
另一家國內AI創業公司MiniMax(稀宇)也于1月15日推出MiniMax-Text-01,基準測試結果顯示,性能比肩GPT-4o和Claude-3.5,價格為輸入每百萬Token0.2美元(1.45元人民幣),輸出每百萬Token1.1美元(8元人民幣),和DeepSeek-V3幾乎持平。
當然,也有分析人士指出,雖然價格較高,但閉源大模型OpenAI GPT-4o和Claude 3.5-Sonnet在多模態、泛化能力以及綜合能力上的優勢依然存在,不少開發者暫時還不會放棄。
英偉達模組出現低價拋售
同時,隨著DeepSeek開源模型的廣泛應用,國產GPU服務商迎來新一輪增長機遇,算力市場格局也正經歷深刻變革。
當下,國內多數企業都在自行部署DeepSeek。其中DeepSeek滿血版模型對顯存要求較高,需要1.25臺H100或1臺H200支持,但4位量化版僅需400GB左右的顯存。上述人士透露,有客戶已經在國產GPU服務器上做本地化部署的適配,從成本上來說,雖然仍需數萬元,但較之前已大幅降低。
據了解,目前亞馬遜和阿里云平臺已有服務商在低價拋售H100模組,上述人士分析,此前生成式AI大模型廠商選擇英偉達,是因為其成熟的CUDA生態和GPU的通用能力,也是當時性價比最高的方案,因此大廠爭相堆砌算力資源。“小力同樣也能出奇跡”的DeepSeek靠算法突破算力限制,且客戶需求逐漸向推理和微調轉移,國產GPU適配性正在提升,從而擠壓了英偉達的部分市場空間。
DeepSeek的API商業化,本質上是一場深刻的“技術效能革命”。彭璐認為,DeepSeek的出現,推動算力市場開始思考如何從“堆算力”轉向“精細化運營”,企業更注重單位算力的效能,市場供需平衡正在重構。同時,DeepSeek的開源策略也降低了AI應用的門檻,未來入局AI賽道的中小企業或會大幅增加。
排版/ 季嘉穎