
文丨獵云網 孫媛
AI圈的當紅辣子雞,已經引發了廠傳廠“交友”的現象級表現。
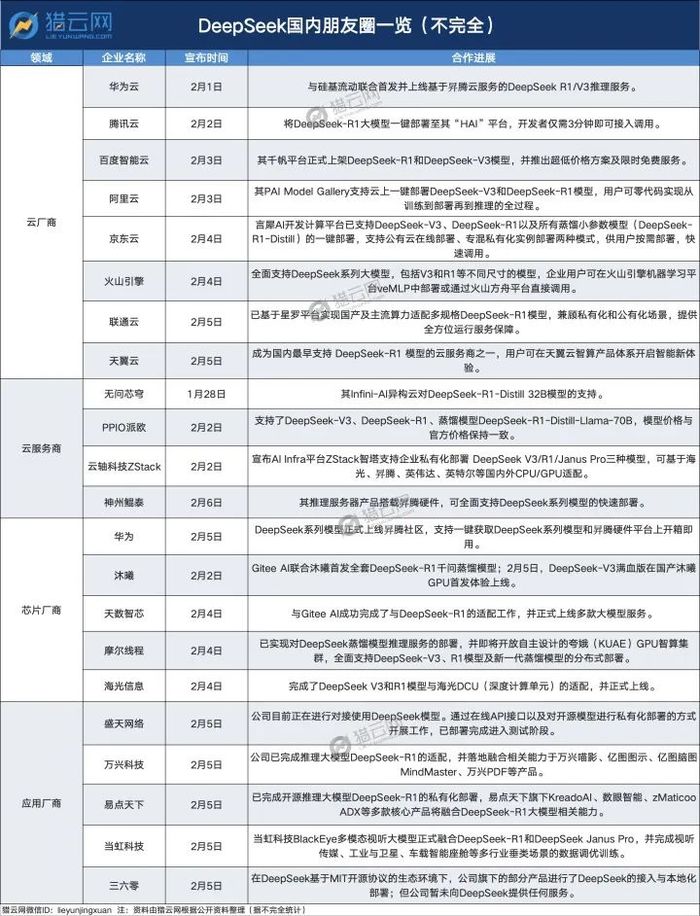
國內,云廠商跑得最快。
2月1日,華為云就打響第一槍,隨后騰訊云、阿里云、百度智能云、京東云、聯通云等主流云平臺也相繼宣布接入DeepSeek系列模型。
同期,DeepSeek的這股“接入熱”還蔓延到了各大芯片廠商、應用端企業,呈現出“提速”態勢。
短短一周內,不僅海光信息、摩爾線程等芯片廠商宣布適配上線,上市公司奇安信、視覺中國、易點天下、盛天網絡、神州數碼、萬興科技等更是密集宣布:接入DeepSeek。
而這股“交友”熱潮在國內還算是“雖遲但到”。
要知道,早在1月底,微軟、英偉達、亞馬遜、英特爾、AMD等海外巨頭們就相繼擁抱,紛紛跟DeepSeek牽起了手。
何以至此,還得從今年春節DeepSeek的一炮而紅談起。
半個月前,國產開源大模型DeepSeek-R1正式發布,在數學、代碼、自然語言推理等任務上性能對齊OpenAI-o1正式版,可謂一鳴驚人。
更關鍵的是,DeepSeek-R1用的還是更經濟的計算資源,推理成本僅為OpenAI-o1的幾十分之一,其開源的路徑,更是降低了各領域AI應用的研發成本,可以有效加速大模型應用創新和普及。
這也就意味著以低成本已可訓練出足夠好的AI模型,這將是一場通往AGI時代的技術普惠。
眾所周知,AI界苦降本增效久矣,打出“高性能、低成本”牌的DeepSeek,自然成為了香餑餑。
他們,都在跟大模型黑馬“交朋友”
截至目前,DeepSeek“朋友圈”的企業可一分為三來看。
首先,是春江水暖鴨先知的云廠商們,每天都有新人在官宣進場。
國內云服務廠商無問芯穹來的最早,在1月28日除夕一大早宣布了其Infini-AI異構云對DeepSeek-R1-Distill 32B模型的支持。
隨后四大云巨頭中,當屬華為云最快。
2月1日就在官微宣布,與硅基流動聯合首發并上線基于昇騰云服務的DeepSeek R1/V3推理服務,表示“其性能可與全球高端GPU部署模型相媲美”。
騰訊云阿里云,則分別以“開發者僅需3分鐘即可接入調用”“用戶可零代碼實現從訓練到部署再到推理的全過程”主打“一鍵部署”的高效。
百度智能云靠“卷”出圈,早早打出低價牌,推出“超低價格方案及限時免費服務”。
京東云跟聯通云則劃出“按需部署”的關鍵詞,前者“支援公有云線上部署及專混私有化實例部署兩種模式”,后者“兼顧私有化和公有化場景,提供全方位運行服務保障”。
從云廠商的角度來看,他們率先與DeepSeek實現深度對接,無論是為了構建AI生態,豐富平臺的AI服務、還是降低成本,亦或是吸引開發者、滿足客戶的多樣化需求,快速接入最火的大模型,都是筆劃算的買賣。
再到芯片廠商,更是全球聞風而動,為DeepSeek提供算力支持。
這里面,不在春節假期的海外公司占了先機。
1月31日,英偉達宣布,NVIDIA NIM已經可以使用DeepSeek-R1。同日,微軟稱已將DeepSeek-R1正式納入Azure AI Foundry。亞馬遜云科技(AWS)也宣布:企業和開發者可以在Amazon Bedrock和Amazon SageMaker AI中部署DeepSeek-R1模型。
2月2日,沐曦聯合GiteeAl發布全套Deepseek-R1千問蒸餾模型,DeepSeek-V3滿血版在國產沐曦GPU首發體驗上線。
隨后在2月4日,摩爾線程、天數智芯、海光信息同天入局,其中,海光信息技術團隊已完成DeepSeek V3和R1模型與海光DCU的適配并上線,摩爾線程也宣布,已實現對DeepSeek蒸餾模型推理服務的部署。
此外,DeepSeek系列模型首發即支持昇騰平臺,神州數碼旗下神州鯤泰推理服務器產品搭載昇騰硬件,可全面支持DeepSeek系列模型的快速部署。
而這場AI盛宴,應用端自然也不會缺席。
在網絡安全應用上,奇安信自研QAX安全大模型通過DeepSeek-R1進行了一系列的優化和蒸餾,運營成本實現了大幅降低,同時在威脅研判等多個場景下的模型性能方面獲得了顯著提升。
其中安全專業問答整體性能分數提升約16%,極大提升了智能威脅分析和決策的準確度。
數字創意軟件公司萬興科技2月4日也宣布,旗下視頻創意、繪圖創意及文檔創意軟件業務多款產品完成了與DeepSeek-R1的深度適配,包括萬興喵影、億圖圖示、億圖腦圖MindMaster、萬興PDF等。
此外,在應用側接入DeepSeek的相關企業還有推動視覺內容服務領域AI技術應用進一步升級的視覺中國、智能營銷服務商易點天下、智能視頻解決方案與視頻云服務商當虹科技以及互聯網和移動安全產品及服務提供商三六零。
從云到芯片再到應用,DeepSeek卷起的全球AI風暴,已然深度卷進產業中的每一位玩家。
來源:獵云網
“AI界拼多多”,要走出一條生態路
值得注意的是,DeepSeek的爆火,并不是偶然。
這還得從它的基因說起。
據天眼查顯示,DeepSeek公司全稱為“杭州深度求索人工智能基礎技術研究有限公司”,簡稱“深度求索”,成立于2023年7月,公司股東為寧波程恩企業管理咨詢合伙企業(有限合伙)(即知名量化資管巨頭幻方量化)和創始人梁文鋒。
從股東便可看出,彼時下場大模型的深度求索,有的是量化基金的背景,在一眾AI大牛創業中,有點宛如異類。
但是優勢也非常明顯:資金、團隊、硬件,它齊了。
幻方量化于2015年成立,通過AI技術優化量化投資策略,2021年公司管理規模就突破千億元,成為國內量化私募四巨頭之一。
也由此,梁文鋒跟團隊積累了量化投資和高性能計算領域的深厚背景和豐富經驗,同時伴隨的還有AI能力。
根據《財經十一人》內容,2023年國內擁有超過1萬枚GPU的企業就包括了幻方量化。早在2019年,幻方就成立了AI團隊,自研深度學習平臺。
這些,都足以讓深度求索在大模型圈低調前行。
當時,在《暗涌》的文章中,幻方目標很明確,“深度求索”強調專注做真正人類級別的人工智能,目標是研究——開源——推動行業發展,最終通向AGI。
在文章中,梁文鋒更是堅定認為“OpenAI不是神,不可能一直沖在前面”。
這些都奠定了DeepSeek的基調,不是模仿,而是原創,不是學徒,而是挑戰者。
成立半年后,第一代大模型DeepSeek Coder便發布,同月還率先開源中國首個MoE大模型(DeepSeek-MoE)。
2024年5月,其第二代開源Mixture-of-Experts(MoE)模型——DeepSeek-V2面世,因為DeepSeek V2模型因在中文綜合能力評測中的出色表現,且以極低的推理成本引發行業關注。
也是這一次,DeepSeek有了“AI界的拼多多”之稱。
去年底,全新系列模型DeepSeek-V3首個版本上線并同步開源,根據公開信息,DeepSeek V3的表現幾乎追上了Anthropic Claude 3.5 Sonnet和OpenAI GPT-4o。
連Meta AI研究科學家田淵棟都給出了贊賞,稱“這是一項了不起的工作”。
再到成本上,官方技術論文更是披露,DeepSeek-V3模型的總訓練成本為557.6萬美元,而GPT-4o等模型的訓練成本約為1億美元。
強烈的成本對比之下,直接讓DeepSeek譜寫了AI界的新神話。
彼時,深度求索對外表示,“這是一個全新的開始。”也由此,DeepSeek在AI圈開始有了些許聲音。
今年1月20日,DeepSeek-R1模型正式發布,并同步開源模型權重。與此同時,DeepSeek應用(不包含網站數據)上線5天日活就已超過ChatGPT上線同期日活,成為全球增速最快的AI應用。
隨后,乘著超預期的產品體驗帶來的口碑裂變,DeepSeek迎風而上,在1月28日發布開源多模態模型Janus-Pro。
其中,70億參數版本的Janus-Pro-7B模型在使用文本提示的圖像生成排行榜中優于OpenAI的 DALL-E 3和Stability AI的Stable Diffusion。
截至2月2日,DeepSeek登頂140個國家的蘋果App Store下載排行榜首位。到2月4日,上線20天,DeepSeek日活突破2000萬,創下新紀錄。
C端的火爆,自然也為B端的國內外生態圈快速搭建埋下伏筆。
手持低價和開源并行的策略,無疑成為DeepSeek朋友圈引爆的催化劑。
而建立更大更完善的生態,正是DeepSeek發展的未來所在。
近日,梁文鋒對《暗涌》說,在這波AI浪潮中,DeepSeek的出發點是走到技術前沿,去推動整個生態發展。他們只負責基礎模型和前沿的創新,其它公司在DeepSeek的基礎上構建toB、toC的業務。
正如英偉達的領先不只是一個公司的努力,也是整個西方技術社區和產業共同努力的結果。
他說,“中國AI的發展,同樣需要這樣的生態。”