

文|硅谷101
ChatGPT以及硅谷AI大戰終于升級,長出了“眼睛”和“嘴”。5月中旬,OpenAI和谷歌前后發布重磅AI多模態更新,從基于文字交互的ChatGPT全面升級,實現了“聲音,文字和視覺”三者全面結合的人工智能新交互功能,而這,也標志著硅谷科技巨頭的生成式AI之戰正式進入到第二輪。新一輪競爭,只會更加激烈、更加全面。

大家好,歡迎來到硅谷101,這次我們聊聊這次多模態AI之戰對科技巨頭們的商業版圖意味著什么變化,以及生成式AI智能技術的下一步會發生什么。那我們首先來快速復盤一下OpenAI和谷歌發布的多模態重磅更新。
01、OpenAI GPT-4o:低延遲語音交互,《Her》成為現實
OpenAI這次的發布時長很短,全程就26分鐘,發了一款產品GPT-4o。
GPT-4o的“o”是拉丁詞根“Omni”,意思是“所有的”、“全部的”或“全能”,意味著文本、音頻和圖像的任意組合作為輸入,并生成文本、音頻和圖像輸出的能力,這樣的“全面”多模態能力。


說實話,2024年AI之戰會升級到多模態產品,這個預期在2023年已經是行業共識,我們在之前多期視頻都提到過,僅僅是文字的prompt很難表達人類的意圖,非常低效也非常受限,所以有語音和視覺的加持的多模態AI交互是人類通往AGI道路上的必經之路。但當多模態AI交互真的到來的時候,我覺得還是會被震撼到。
OpenAI說,GPT-4o可以在232毫秒內響應音頻輸入,平均為320毫秒,這已經達到人與人之間的響應時間。也就是說,AI語音對話的交互已經能做到非常低延遲、很絲滑的像真人一樣對話了。
GPT-4o發布之前,ChatGPT的語音模式功能有著好幾秒的延遲,這讓整個交互體驗非常差,這是因為之前的GPT系列的語音功能是好幾個模型的拼合,先把聲音轉錄成文本,再用GPT大模型接受后,輸出文本,然后再用text to speech模型生成音頻,但這其中會損失非常多的信息,比如說語調,語氣中的情緒情感,多個說話人的識別,背景的聲音等等,所以語音功能會很慢很遲緩也很基礎。
而這次,GPT-4o是OpenAI專門訓練的跨文本、語音和視覺的端到端新模型,所有輸入和輸出都由同一個神經網絡處理,這使得GPT-4o能夠接受文本、音頻和圖像的任意組合作為輸入,并生成文本、音頻和圖像的任意組合輸出,是兼具了“聽覺”、“視覺”的多模態模型,同時還支持中途打斷和對話插入,且具備上下文記憶能力。
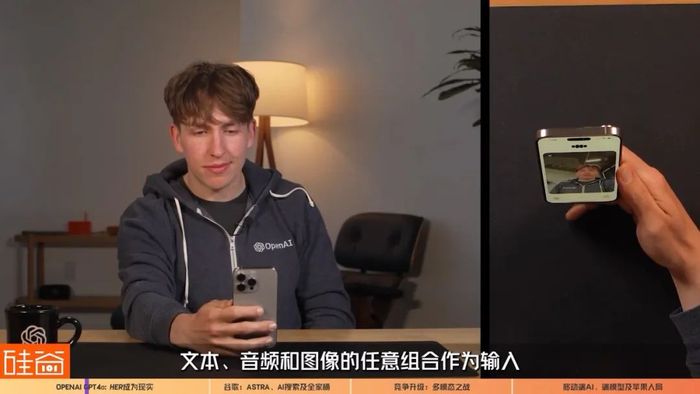
這樣的多模態模型是OpenAI首次發布,表示還有很多探索的空間,但目前展現出的功能已經讓人驚喜。比如說,在現場demo中,GPT-4o可以理解人們的呼吸急促聲音并用輕松的方式安慰人類。

它可以識別人臉表情,以及辨認情緒。

它可以隨意變換語氣和風格來講故事。

同時,GPT-4o還可以通過硬件設備通過視覺來分析人們正在從事的工作、看的書,可以引導人們解題,可以切換語言實時翻譯,也能通過視覺識別給它的信息并且給出非常擬人化的反饋。

說實話,在直播發布會中直接現場演示這件事情是很需要勇氣的,因為一旦出錯會引發非常大的公關災難,但OpenAI有這個勇氣去直接現場演示直播,給人的感覺非常自信。除了現場的演示之外,OpenAI還在官網上放出了更多更復雜場景的交互,展現出AI多模態的更多的潛力。
比如說,在官網上OpenAI做了17個案例展示,包括了照片轉漫畫、3D物體合成、海報創作、角色設計等樣本。
此外,OpenAI總裁Greg Brockman的演示視頻中,GPT-4o可以識別出他所穿的衣服、身處的環境、可以識別出Brockman的情緒和語氣和房間里正出現的新動作,但最讓外界關注的一個動作是,讓兩臺運行GPT-4o的設備進行語音或視頻交互。
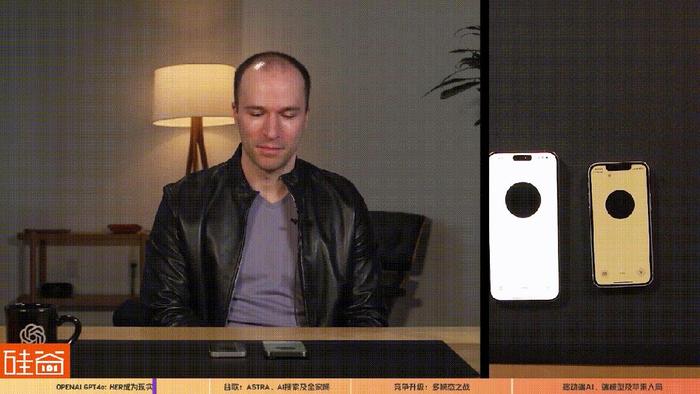
也就是說,OpenAI的GPT-4o多模態給了AI交互的聲音和視覺,不僅升級了人和AI之間的交互,也升級了AI和AI之間的交互,這樣的交互更自然,更擬人,有著更大空間的應用場景。而且整個AI的聲音和語言非常的靈動,機器人感比較弱,會開玩笑會安慰人會害羞,難怪很多人在OpenAI發布會之后直呼,那部講述人類和AI語音助手Samantha電影《Her》的時代真的到來了。

戴雨森
真格基金管理合伙人
我自己是非常激動的啊。因為我一直覺得我們對于 AI 落地的應用預期,其實不一定是準確的,大家可能在AI一開始的時候,覺得生產力的場景也很直接,但是現在可能發現,很多(AI)Agent(人工智能體)的落地反而比較難,但是感性的角度反而會更加容易一點。
對于絕大部分人來講,生活其實是單調的,或者是一成不變的,是乏味的。那這個時候其實不管像 《Her》 里面說所謂的這種,男女情感的表達,還是說一種陪伴、一種傾聽,其實都是很稀缺的一種資源或內容。當 AI 能夠做到以一個低延遲、低成本,很好的形式去表達這種情緒價值的時候,這可能會對我們的社交社會帶來很大的影響,也會帶來很大的這個機會。
隨著AI能力的提升,圖靈測試這個概念會越來越模糊化,電影Her中描述的場景實現幾乎是早晚的事。但AI多模態帶來的不僅僅是情感上的陪伴和交互,更多的是整個工作場景和生態上的顛覆。
就在OpenAI發布會的一天之后,谷歌發布的一系列多模態更新,進一步的說明了AI多模態能帶來的顛覆性潛力。
02、谷歌的戰書:Project Astra及"120次AI"的全生態升級
對比起OpenAI的發布會,谷歌的發布會就更像一個巨頭了:長達兩小時,在各個生態方向用AI發力。連CEO Sundar Pichai自己也說,整場Keynote的演講稿里總共提了120次“AI”,表明谷歌目前所有的工作都圍繞多模態AI模型Gemini來展開。

首先,直接與OpenAI前一天發布的GPT-4o對標的是Project Astra。

2.1 語音助手Project Astra
雖然谷歌不是現場演示,不像OpenAI那么敢,畢竟巨頭還是需要保守一些,但從谷歌的demo視頻來看,如果谷歌的demo是實時生成的,谷歌的Gemini多模態模型比起OpenAI在功能上也不算弱。
谷歌DeepMind負責人Demis Hassabis在臺上宣布了Project Astra,Project Astra基于Gemini多模態大模型,是一個實時、多模態的人工智能助手,可以通過硬件設備“看到”世界,知道東西是什么以及你把它們放在哪里,并且可以回答問題或幫助你做幾乎任何事情。在谷歌的demo視頻中,谷歌倫敦辦事處的一名工作人員用Astra識別自己的地理位置,找到丟失的眼鏡,檢查代碼等等。

如果谷歌demo是實時拍攝的,反正Demis Hassabis是打包票說這個視頻沒有任何篡改,那么毫無疑問這會解鎖眾多的交互場景。Hassabis說,“展望未來,人工智能的故事將不再是關于模型本身,而是關于它們能為你做什么”。
而與OpenAI的GPT4o宣戰的Project Astra只是其中的一個產品而已,谷歌其實發布了非常多的更新,包括谷歌展示了最新版Gemini加持的搜索功能。
2.2 AI搜索
谷歌首先在美國上線名為AI Overviews的AI技術生成摘要功能。簡單來說,在你搜索信息的時候,谷歌的AI就直接幫你查找、整理和展示了。具體來說,通過多步推理,Gemini可以代替用戶研究,實現更好更高效的搜索總結和結果,比如說規劃一日三餐,購物餐廳選擇,行程規劃,都可以在AI搜索中完成,更重要的是,這樣的AI搜索還會直接幫你做規劃,比如說“幫我創建一個3天的飲食計劃”,谷歌AI搜索就直接一個計劃書擺在你面前了。
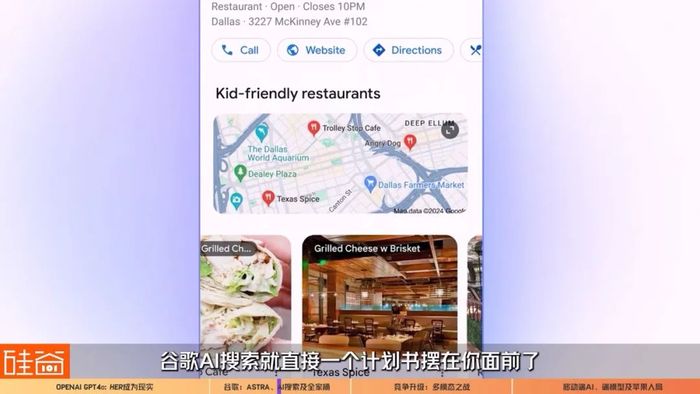
另外讓我覺得很期待的兩個功能,一個是多模態搜索。你會不會遇到過這種情況,搜索時發現難以用語言描述問題,或者遇到不熟悉不認識的物體,不知道如何去搜索相關的名詞。
現在你就可以直接拍張照片或者錄段視頻用語音或打字問AI搜索,這個是啥,怎么修理,之后谷歌就會幫你整理出相關的各種信息。

對于我這種3C殺手、經常容易弄壞各種電器的人來說,我簡直太期待這個多模態搜索功能了。而多模態模型Gemini的強大搜索和推理能力還能做更多的事情,也正好是我的痛點。
比如說,CEO Pichai在現場演示,Gemini可以在谷歌相冊Google Photos里進行更多的相關搜索,比如通過名為Ask Photos with Gemini的新功能讓Gemini找到用戶想要的車牌照號。

實話告訴大家,我就是那個記不住我家車牌號的人,所以,谷歌Gemini可以在用戶的相冊中搜索,找到相應信息和對應的照片,比如說獲取照片中拍到的車牌照號碼,這個功能對我來說,真的是非常期待。以及任何可以幫我尋找以往照片、文 件中信息的功能,我覺得都會解決很多痛點。
還有一個對我來說很大幫助的是,谷歌AI將會結合到谷歌的所有workspace中,俗稱“谷歌全家桶” ,也就是說,在 Gemini 的加持下,Google Workspace,包括 Gmail、Google Docs、Google Drive、Google Calendar、Google Meet 等都可以打通,可以在這里進行跨文檔搜索。比如說,你在郵箱里收到了一張發票,那么可以直接通過Gemini,把這張發票,整理到網盤Google Drive和表格Google Sheet中。還可以在郵件中搜索、讀取信息和亮點、歸納總結,這些功能都會在今年稍后推出。
另外谷歌還發布了一系列其他的模型更新,包括畫圖的 Imagen 3,音樂的 Music AI Sandbox,還有生成視頻的 Veo,還有有史以來最長、上下文窗口200萬token的Gemini 1.5 Pro,還有Gemini app以及谷歌的自研芯片第6代 TPU等等,因為細節和產品太多了這個視頻我們就不一一復述了,如果感興趣的小伙伴可以去看看谷歌的兩小時發布會全程。
看到這里,你可能會問,在OpenAI之后發布這一系列重磅更新的谷歌,兩個對手這一輪的發布,誰是贏家呢?
03、OpenAI vs. Google:多模態之戰與AI的應用落地
兩場發布會之后,我看到不少人在對比OpenAI和谷歌的產品發布。我們從公司策略層來解讀一下。
首先,OpenAI比谷歌IO早一天發布了春季更新,而且非常臨時,很難猜測不是故意搶在谷歌前面的,發布時長也只持續26分鐘,非常聚焦在GPT-4o這一個產品上。雖然外界對GPT-4o的評價沒有說像當時發布ChatGPT時那么驚喜那么轟動,但不得不說,業內的很多人還是覺得是一個很重要的里程碑,雖然多模態的這些功能是去年業內共識,OpenAI會在2024年做出來并發布,并沒有那么多驚喜或創新,但是“實現”了大家“期待中早晚會實現的AI更新”,也是非常有意義的,并且也是正確的發展道路。
Howie Xu
AI及云服務行業高管、斯坦福大學客座教授
OpenAI這個GPT 4模型出來,也能夠做些translation(翻譯),翻譯什么的并不是一個新東西,如果沒有實時效應,其實是很難落地,但星期一他那個宣布的東西,讓我感覺到我有可能真的會去用,比如下次我跟你一起去采訪誰或者跟誰講話,語言不通(的時候),我們真的可能就打開我們的手機來給來用translation。就以前的,那個延遲這么慢,效果很不好,你都不好意思拿出來就用對吧?
那為什么能夠做到延遲性這么低,那被廣泛認為的就是因為它是做到了Native(原生的)Multimodal(多模態模型),我看到那個demo,我的第一反應是說OK,以前他說的這些東西我都是玩玩是可以的,但是我是不會拎出來用的,但是他星期一給我的東西,我就覺得有可能我會拿來,就在實際的生活工作的場景里面可能用得到。

如果光從語音助手這個產品上來看,GPT-4o對打谷歌Project Astra,目前業內很多聲音仍然認為OpenAI是領先的。單從多模態模型上來說,GPT-4o是OpenAI第一款完全原生的多模態模型。
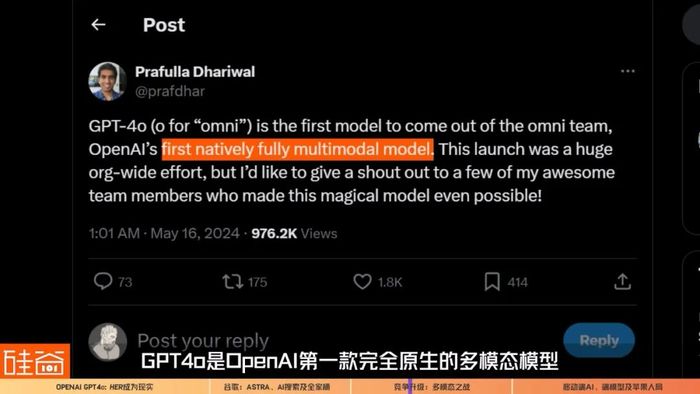
我們視頻之前也說到,它所有的多模態輸入和輸出都由同一個神經網絡處理,這使得GPT-4o能夠接受文本、音頻和圖像的任意組合作為輸入,并生成文本、音頻和圖像的任意組合輸出,是所謂的“multimodal in(多模態輸入), multimodal out(多模態輸出)”。
但目前不少業內人士認為,谷歌的Gemini目前并沒有做到這個程度,比如說英偉達高級科學家Jim Fan在LinkedIn上發表觀點認為,谷歌是多模態作為輸入,但并不是多模態作為輸出(multimodal in, but not multimodal out)。
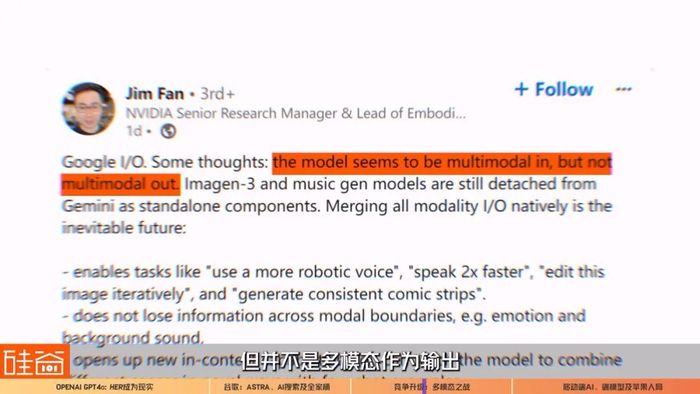
這意味著谷歌本次更新的視頻、音樂等模型依然是獨立于Gemini大模型的存在,只是輸出的時候把所有模型給整合起來擁有的多模態輸出能力。所以Jim Fan認為,谷歌整合所有的輸入輸出模態,將是不可避免的未來發展。
但他還有一句評論挺有意思的,Jim Fan說,谷歌在這次發布會中做對的一件事是:“他們終于認真努力將AI集成到搜索框中。谷歌最堅固的護城河是分銷,Gemini不一定要成為最好的模型,才能成為世界上被使用最多的模型。”

也就是說,谷歌在整個生態中只要順暢的融入AI功能,讓用戶覺得能解決問題,提高生活和工作效率,因為谷歌在搜索、郵箱、谷歌云上的種種積累和優勢,谷歌的分銷優勢依然能保證谷歌在AI時代中立于不敗之地。
所以,按照這個邏輯來看,谷歌在這次發布會上在全生態上全面升級AI功能,其實是做到了。所以,就算OpenAI前一天搶跑發布亮點的GPT4o,谷歌整體來看,這一局也不算輸,第二天的股價穩中上漲也應證了市場的看法。
戴雨森
真格基金管理合伙人
OpenAI發布會之后,Google 發布會之前,我跟一位Google的同學聊,然后他提到一個觀點還挺有意思。他說一年以前OpenAI發GPT4的時候,他們有很多東西,他們是不知道OpenAI怎么做到的,覺得哇他們好厲害,現在OpenAI發布會發了之后,他們看到是說,這個東西我們也知道怎么做,但我們可能還沒有像他那樣做得那么好,或者那么ready(準備好)去demo,所以我覺得目前來看的話,他們肯定在這上面是有一些這個經驗,所以我感覺就是雙方的絕對差距還是在縮小的。
Howie Xu
AI及云服務行業高管、斯坦福大學客座教授
相對來講,Google注重的是一個solution(解決方案),就是解決方案,那個OpenAI目前注重的,更多的還是一個technology(技術),它在technology(技術)上面非常的驚艷,但你說他怎么去跟我們人的日常,不管是生活、工作去結合起來,他沒有那么多的人力,他也沒這么多思考,而且這不是他的強項。
Google IO的那個發布,看上去可能從某些角度來講,好像還沒有那個前一天,OpenAI的東西那么驚艷,但實際上我覺得很驚艷,我覺得驚艷不只是說是一個model(模型)的驚艷,model只是一個維度,還有其他維度,怎么跟我的生活、工作能夠結合起來,比如說跟我的手機結合起來,它一些的announcement(發布)是這個技術,所以說AI這件技術,我覺得今天落地是一個很大的一個挑戰,或者說一件事情。
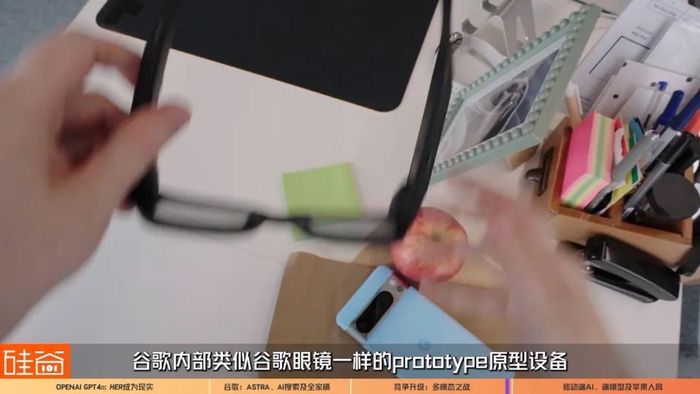
所以可以預期到,接下來,多模態的繼續整合和優化,以及將AI功能整合到谷歌的各個產品中,以及AI agent(人工智能體)的引入,將會是谷歌發力的重點。除此之外,這兩場發布會聽下來還讓我非常感興趣的一點是,硬件。
OpenAI整個demo用的是蘋果手機和蘋果電腦,谷歌用的是安卓手機和硬件,同時還在視頻demo中提到了一個谷歌內部類似谷歌眼鏡一樣的prototype原型設配,所以接下來,硬件和AI大模型的整合,也到了加入戰場的時刻。而這個賽道的老大,蘋果,在干什么呢?
04、移動端AI大戰開啟,蘋果即將入局?
雖然蘋果公司在這輪硅谷科技巨頭AI大戰中遲遲沒有發聲,但最近有不少的輿論風向稍微給我們勾勒出了蘋果潛在的想法和布局。
目前市場都在等待6月10日舉行的蘋果2024年全球開發者大會WWDC,預計會在屆時會宣布一系列在AI和硬件上的產品發布。

包括可能會和OpenAI合作,將ChatGPT整合到 iOS 18 操作系統,此外,外界期待蘋果會宣布利用大模型全面升級Siri,給用戶提供AI賦能的交互體驗,還有蘋果如何將大模型塞進手機移動端的“蘋果全家桶”,也是馬上召開的蘋果發布會的最大看點。
今年早前,蘋果發布了一系列的論文,包括第一個手機端UI多模態大模型Ferret-UI。

還有今年一月發布的一篇將大模型塞進 iPhone 的關鍵性論文,“使用有限的內存實現更快的LLM推理”。

還有這篇,蘋果Siri團隊在論文《利用大型語言模型進行設備指向性語音檢測的多模態方法》中討論了去掉喚醒詞的方法。

同時, 在今年3月發布的另外一篇論文中,蘋果首次披露一個具有高達 300 億參數的多模態模型MM1,這個多模態能力如果集成到iPhone 上,就能能夠通過視覺、語音和文本等多種方式理解并響應用戶的需求。
所以綜上所述,雖然近兩年來,蘋果時常為人詬病在 AI 領域動作遲緩,但是感覺,蘋果是在等一個正確的時機來加入戰局,它并沒有落后,而是一直在等待。如今,多模態技術成熟,特別是文字輸入、語音和視覺的交互和手機等硬件是天然的適配,OpenAI和谷歌的AI多模態之戰打響之際,也是蘋果入局的時間了。
戴雨森
真格基金管理合伙人
如果你看互聯網和移動互聯網時代,其實它們在軟件的滲透上,都要疊加一個硬件的滲透,大家要買PC、手機,所以導致,之前軟件的滲透速度,其實是相對比較慢的,那為什么ChatGPT一出來就滲透到了這么多的用戶,實際上是因為它跑在一個,比較成熟的硬件上。所以我覺得在目前來講,AI落地肯定首選還是在手機上,我肯定是期待像AI的這些模型,怎么樣在蘋果的生態系統中去落地,其實說全新形態的硬件,我自己覺得可能性比較低,但是在這個上面有了,包括最近剛發M4 對吧,大家說iPad這個上面有這么強的這個芯片,你如果還是做原來的任務,是不是就浪費了,你是不是用來干一些AI的任務呢
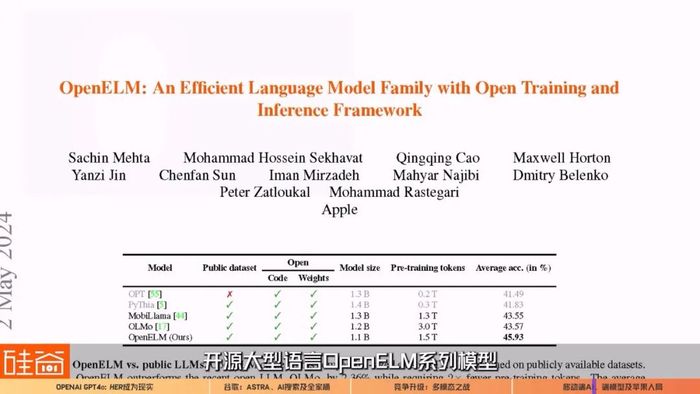
而對于智能手機、智能手表、乃至于以后的VR和AR眼鏡設備,更小的端模型將是業界著重發力的重點。在今年4月,蘋果宣布在全球最大AI開源社區 Hugging Face 發布了全新的開源大型語言OpenELM系列模型,包括4個不同參數規模的模型:270 Million(百萬)、450 Million(百萬)、1.1 Billion(十億)和3 Billion(十億),沒錯,最大的也只有30億個參數,對移動端小模型的布局有著明顯的意圖。而Howie Xu在采訪中認為,端模型是人類應用AI發展的必然趨勢。
Howie Xu
AI及云服務行業高管、斯坦福大學客座教授
個人非常看好端模型,因為過去一年我們大量的精力、討論都是在越大越好,但是萬億級的parameter(參數),不適合放在手機上面,那另外一個問題就是說,那個不是萬億級的,千億級的,或者百億級的參數,是不是能夠把模型做到足夠好。
現在我們看到的很多的小的模型可能是700億參數的,一年之內我們能夠看到就是,十億這么一個參數的一個模型,能夠做到當初ChatGPT出來時候,讓大家驚艷的那個感覺,相當于(GPT)3.5的那個model(模型)的能力,我覺得是一個billion(十億)的parameter(參數)是應該能夠做到。
如果能夠這個端上面能夠運行一個十億參數級別的模型,能夠做到(GPT)3.5的(的能力),那就打開了很多的想象空間,然后接下去會有更小的模型,因為模型總歸是越小,對耗電、對各方面的都有很大好處,我覺得甚至是sub 1 billion(小于10億參數)的會更好,從privacy(隱私)的角度,從耗電的角度,從各方面角度,我覺得小模型是必須的。
文章的最后,我們來總結一下OpenAI和谷歌的這兩場發布會,AI多模態之戰打響之后,在更多更廣的應用上,我們看到了AI殺手級應用的曙光,有了更落地更切實的可用性,這將重塑人類和AI以及電子設備的交互方式。此外,雖然OpenAI和谷歌表面上刀光劍影,但兩家公司的策略目標是有些區別的:前者一路勇向前目標scaling law(規模法則)和AGI,后者更注重自家生態和應用落地來捍衛商業營收與市場分銷護城河——可能模型是不是最好的,并沒有那么重要。所以目前的多模態初戰,OpenAI雖然贏了,但谷歌也沒輸。

而在硬件端,各類硬件與AI的結合將帶來巨大的新機會,而大模型“瘦身”進手機只是開始,打造應用體驗才是關鍵所在。此外,讓人驚喜的是谷歌demo最后展示的AR眼鏡與AI的結合,這給“AR智能眼鏡”這個起起伏伏了好幾個周期的產品,帶來了新的曙光和希望,除了谷歌多年的AR經驗,Meta在AR硬件上的布局,與蘋果在Vision Pro以及自家AR團隊的未來策略,都可能成為下一場科技硬件巨頭們比拼的新戰場。對了,不要忘記微軟這家與OpenAI深度綁定的巨頭,它并沒有將全部雞蛋都放在OpenAI的籃子中。微軟目前在AI布局上的優勢,加上在軟硬件上都有多年經驗和布局,最近還收編了之前主打情感陪伴大模型公司Inflection的大部分AI頂級人才、發布了自己的大模型MAI-1。所以我們很興奮得能感覺到,生成式AI的第二輪多模態戰役打響了,越來越多的科技巨頭入局,并且戰術和方向也越發清晰,也帶來的是AI應用的潛在落地與爆發。這場戰斗,硅谷101在最前線,我們拭目以待。