

文|經緯創投
如果要問AI的下一個黃金賽道是什么?黃仁勛的答案是生命科學。
他在很多場合明確表達了這個觀點,比如在一場“世界政府峰會”的會議中,他說:“每個人都要學習電腦的時代已經結束了,未來的世界應該是生物學。”
在另一場會議的問答環節中,他說如果有重來一次的機會,他會首先考慮生物學,特別是和人類相關的生物學。
不僅僅是黃仁勛這么說,英偉達對外投資也證明了這一點。近兩年,英偉達近乎瘋狂地在醫療和藥物發現領域投資,已投資了超過十幾家初創公司。
據WSJ報道,Moon Surgical是一家利用AI改進腹腔鏡手術的法國創業公司,其首席執行官Anne Osdoit說,她的公司大約在三年前就開始與英偉達合作,當時該公司正在為生命科學領域開發芯片。她說,這種合作關系最終促成了投資,英偉達還幫助公司解決了有關手術機器人的技術監管擔憂。“英偉達非常務實,直接說‘嘿,告訴我們你需要什么’。”

英偉達醫療保健副總裁Kimberly Powell甚至直言:“既然計算機輔助設計行業捧出了第一家2萬億美元市值的芯片公司,計算機輔助藥物發現行業,為什么不能打造下一個價值萬億美元的藥物公司呢?”
在今年英偉達GTC大會上,與醫療保健/生命科學相關的活動將達90場,也突顯了英偉達對生命科學領域的重視。“我們是相當內行的投資者。”今年1月,黃仁勛在一場摩根大通醫療健康會議上說,“如果你在計算或AI方面有困難,請給我們發郵件,我們隨時為你服務。”

英偉達的對外投資中,醫療保健和生物技術類非常多
創新藥研發一直都費時費力,業界有一個著名的“雙十定律”,即研發一款新藥需要10年時間、10億美元,并且成功率也只有10%。所以哪怕是微小的改進,也將價值連城。
科學家們一直在努力用傳統的統計工具,來嘗試改進效率,機器學習使篩選成堆的信息成為可能。比如谷歌DeepMind曾利用其AlphaFold系統,來預測蛋白質結構。這項技術的最新進展出現在5月8日的《自然》雜志,新推出的AlphaFold 3不僅能夠模擬蛋白質與其他分子的相互作用,還能準確預測包括DNA、RNA、配體等生物分子結構以及它們如何相互作用,這項技術能改變我們對生物世界和藥物發現的理解。
下面我們來看看 AlphaFold 3 令人興奮的一些預測結果:
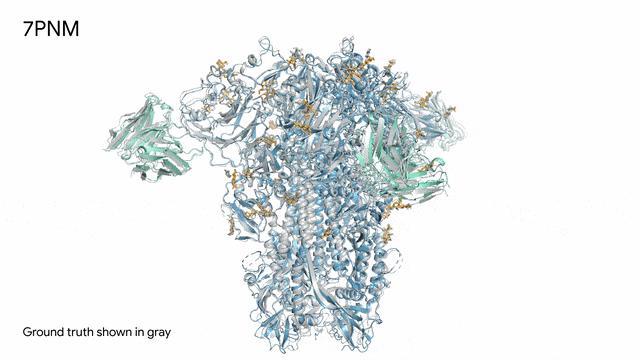
7PNM - 一種普通感冒病毒的突起蛋白(冠狀病毒OC43):隨著病毒蛋白(藍色部分)與抗體(綠色)和單糖(黃色)相互作用,AlphaFold 3對7PNM的預測結果與真實結構(灰色)完全吻合。這能夠增進我們對這種免疫系統過程的了解,有助于更好地理解冠狀病毒,包括COVID-19,從而提高改進治療的可能性。
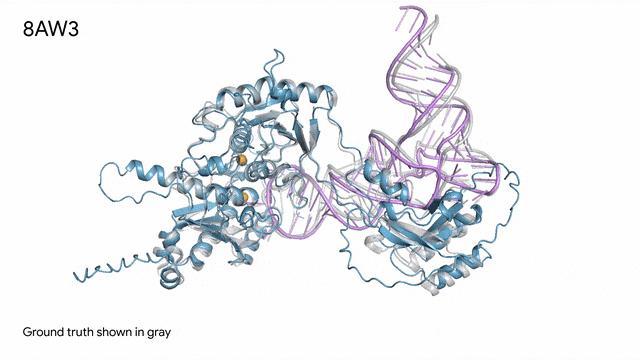
8AW3 - RNA修飾蛋白:AlphaFold 3 預測的由蛋白質(藍色)、一條 RNA 鏈(紫色)和兩個離子(黃色)組成的分子復合物與真實結構(灰色)非常吻合。這個復合體參與了其他蛋白質的生成,這是一個對生命和健康至關重要的細胞過程。

7R6R - DNA結合蛋白:AlphaFold 3 預測的蛋白質(藍色)與 DNA 雙螺旋(粉色)結合的分子復合物,其預測結果與通過復雜實驗得到的真實分子結構(灰色)幾乎完全吻合圖片來源:Google DeepMind
雖然迄今為止只有十幾種藥物在研發過程中使用了人工智能技術,但這一數字在未來可能會迅速增長,未來的藥物研發會越來越像一個計算問題。當數據科學、人工智能和自動化相結合時,生物學將變得工程化,有可能出現指數型改進。
AI 將改變藥物發現過程的每一步,雖然它可能是一種漸進式的改進——這里提升10%,那里20%、30%,但最終將所有這些改進相乘,速度和成功率就可以提高兩到三倍。
今天這篇文章,我們就來聊聊AI在制藥方面到底能做什么?最大的瓶頸——數據,會帶來哪些問題?以及AI制藥更可能會是一種漸進式的變革,而非突變式……Enjoy:
AI在制藥方面到底能做什么?
但為什么現在還沒有獲批藥物,是通過AI方式做出來的?
01 AI在制藥方面到底能做什么?
我們先說一個真實案例。
幾年前,在奧利地維也納醫科大學,一名82歲的病人(保羅)患有一種侵襲性血癌,他已經做了六個療程的化療,但都未能根治。在這個漫長且痛苦的治療過程中,醫生不得不把那些常用的抗癌藥一個一個劃掉,因為它們都沒有起到作用。
最終,保羅參與了一項藥物試驗,一家英國公司Exscientia正在開發一種新型的配對技術,能根據不同患者的細微生理差異,為他們配對所需的精確藥物。
研究人員從保羅身上提取了一小塊組織樣本,將包括正常細胞和癌細胞在內的樣本分成一百多塊,并將它們暴露在不同的藥物組合中。然后,他們利用機器自動化和計算機視覺,這是一種經過訓練的機器學習模型,可識別及預測細胞中的微小變化。
實驗證明,有些藥物不能殺死保羅的癌細胞,有些藥物反而損害了他的健康細胞。最終,這項技術找到了一款抗癌藥物,而此前保羅的醫生沒有嘗試過它,因為往期的試驗表明,這種藥物對治療這種類型的癌癥無效。
最終這款藥物成功了。兩年后,保羅的病情完全緩解,他的癌癥消失了。而如果采用傳統的辦法,實驗的速度和規模不可能這么快。
當然,在這個已經成功的案例里,機器學習只做到了篩選出正確的藥物,這也只是這家英國公司Exscientia的一個小目標,真正的目標是徹底改變整個藥物開發流程,利用人工智能技術設計新藥。
但這個目標還未實現,這是目前整個生命科學界和AI界都在探索的方向。我們希望通過AI和數據驅動的方法,注入更強算力,來提高藥物研發中的成功率。
我們先來看看研發一款新藥(這里主要指小分子藥物)的基本步驟是什么,再來說AI能切入哪些環節。首先,研發人員需要在人體內選擇一個藥物會與之發生作用的靶點,例如蛋白質;然后設計一種分子,對該靶點起作用,比如改變它的工作方式或讓它停止工作。接下來,在實驗室中制造出這種分子,并檢查它是否真的起了作用,并且這個作用是設計所需的作用,而不是其他作用。最后,在人體中進行測試,看它是否安全有效。
幾十年來,研發人員們篩選候選小分子藥物的方法是,將所需靶點的樣本放入實驗室的許多小格子中,加入不同的分子,觀察反應。然后多次重復這一過程,調整候選藥物分子的結構,比如把這個原子換成那個原子,如此反復,這里面依賴的都是研發人員的經驗和直覺。
但從實驗室到人體并不容易,許多藥物分子在實驗室中似乎很有效,但最終在人體中進行試驗時卻失敗了。所以這里面需要大量修改的工作,比如脂溶性不好,就需要修改與脂溶性相關的地方;如果有毒副作用,就需要修改相應的地方克服掉。
新藥研發其實就是一個不斷迭代、修改的過程,最后經過實驗驗證,走向臨床、上市,產生價值。從經驗來看,研發人員可能需要設計和測試20種藥物,才能最終選出一種有效的藥物,這導致研發成本非常之高。
在這個過程中,AI能切入的主要是兩個環節:
第一是在最初選擇苗頭化合物時,就通過AI去篩選。傳統方法是依賴于研發人員的經驗和直覺,只能在一個幾百萬級的化合物庫中去搜索和篩選。據測算,如果剔除一些非常相似的分子,所有的大型制藥公司比如默克、諾華、阿斯利康等等加在一起,最多能有1000萬個分子可以用來制造藥物,其中有些是專有的,有些是眾所周知的。這就是大量化學家在過去百年辛勤工作的總成果。
但自然界中的化合物,或者說成藥空間,有10的60次方,我們實際上只是在一個非常小的范圍內搜索。如果強算力的AI能夠在更大的范圍內搜索,那就能大大突破目前的探索空間,找到更合適的成藥化合物。
這是人工智能的真正潛力所在——打開一個巨大的生物和化學結構庫,這些結構可能成為未來藥物的成分。
第二是在對先導化合物的修改時,運用AI技術修改。在選擇完苗頭化合物后,形成先導化合物,但有很多地方往往需要修改,比如需要把活性修改得更好,或是要把成藥性改得更好,這個環節在藥企研發中可能占了90%的工作量。
如何修改這些分子呢?由于藥物研發已經有了上百年的歷史,我們已經記錄了很多結構的作用,基于這些再去做創新會容易一些。打個比方,這個過程像是要把一幅畫改得更漂亮,但是目前這幅畫中的某一部分,已經畫得還不錯,此前也已經被實驗驗證過了,那就可以保留,在這個基礎上修改。
而經過訓練的AI大模型,它可以從數十年間的幾百萬篇論文和大量檔案中挖掘數據,從這些文件中提取出知識圖譜——哪些改變會導致什么樣的結果,這樣的因果鏈對修改非常重要。
基于這樣的數據基礎,然后就可以讓AI去把其他部分設計出來,讓AI發揮想象力。AI往往比人類專家的想象力更加豐富,人類專家往往只能畫出幾十個分子,而AI生成的數量是沒有上限的,只要算力支持。
并且,在修改中需要同時考慮很多影響因素,比如合成性、活性、成藥性等等,是一個多重目標的復雜問題。人類專家在處理時,往往是簡化,一次只處理一個環節,比如在這個環節只考慮活性,在另外一個環節才去考慮成藥性。但AI能夠更好地處理多重信息。
拿比較重要的成藥性來舉例,比如一款口服針對腫瘤的藥物,它要想進入體內后可以治愈腫瘤,首先需要經過消化系統,然后進入血液和細胞,這個是吸收、代謝的過程;其次藥效需要持續一段時間,并且不能有毒副作用。這些性質統稱為成藥性,是藥物研發中很重要的因素。
以往研發人員主要依賴實驗驗證,這就導致有可能在之前的研發環節花了很多錢,做了很長時間,好不容易發現了一個有效分子,但在成藥性驗證上出了問題,而導致重新做或是放棄,這就造成了“雙十原則”。
如今則可以通過AI+專家經驗+自動化實驗的方式,通過AI提升預測的準確率和設計出更結構新穎、性質更好的分子,來提升整體成功率。有研發人員將藥物和蛋白質在體內的相互作用,視為一個物理問題,模擬原子間的推拉作用,而這種推拉作用會影響分子如何結合在一起,利用人工智能更準確地模擬分子之間的相互作用。
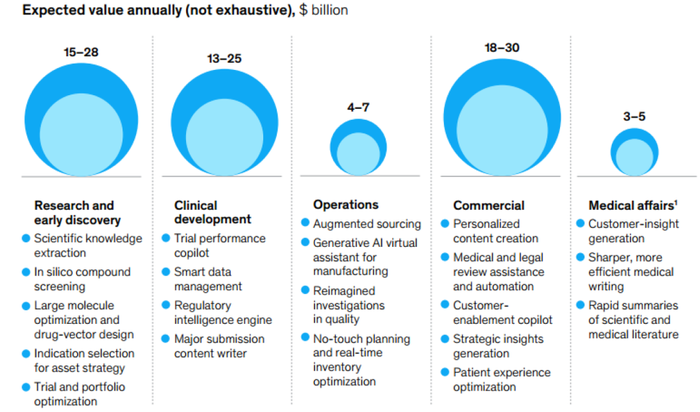
生成式AI對生命科學各環節的作用及經濟價值推動;圖片來源:麥肯錫
02 為什么現在還沒有獲批藥物,是通過AI方式做出來的?
不過,與AI制藥偉大潛力相對應的是一個冰冷的事實,目前還沒有任何一款獲批的藥物,是通過AI的方式做出來的。
“如果有人告訴你,他們可以完美預測哪種藥物分子可以通過腸道或不被肝臟分解,諸如此類,那么他們很可能也有火星上的土地要賣給你。"MIT Review曾經采訪了一位該領域的專業人士。
如今橫在AI制藥技術面前最大的難題是數據,由于生命科學領域的數據非常不標準化,特別是在實驗領域,經常會出現A實驗室做出來的實驗,與B實驗室做出來的實驗壓根沒有可比性。該領域甚至有一個常用語——“Apple to Apple”或者“head to head”,來特別強調可比性。
一旦涉及對真實世界的數據采集,最大的問題就是如何采集足夠多的數據維度。不管是研究細胞還是研究人、動物,一般在傳統生物學、醫學的視角里,采集的都是單點數據,比如這只猴子是胖還是瘦、這個細胞是增殖還是死亡,但這些維度過于單一,對胖瘦、增殖還是死亡的影響因素其實非常多,如果我們缺乏足夠多的觀察手段,以及不能形成多維度、結構化的數據,那么對AI進行的訓練也就會大打折扣。
以及這些數據從哪里來?并不一定是大型藥企,因為以前的數據記錄方式不一定能復用。曾經在自動駕駛領域就有一個經典例子:當我們去尋找可供模型訓練的數據時,很多人最初找到出租車公司,因為出租車都配有行車記錄儀,理論上應該有很多自動駕駛的數據。但實際上大家發現不行,因為出租車缺乏多維度的數據記錄,雖然行車記錄儀的數據有很多,但并不知道當某個路況發生時,司機做出了什么動作,比如怎么打方向盤、什么時候踩了剎車,原來的行車記錄儀并沒有足夠的傳感器去記錄這些內容。所以現在的自動駕駛公司,為了采集多維度的數據,都必須在測試車里加裝很多傳感器。
如今在生命科學領域也一樣,雖然不一定要完全從零開始,但目前的行業數據庫肯定是不夠的,需要加入各種新維度,包括加標準、加定義、加新的“傳感器”等等,需要圍繞AI訓練所需,把各種維度補全,才能夠有訓練好AI的基礎。
而如果從AI大模型scaling law的角度,現在還沒有人知道一個足夠智能的生命科學大模型,到底在哪個范疇上才能夠達到涌現?在沒有足夠高質量的數據、沒有達到scaling law生效前所做出來的AI,歸根結底可能只是overfitting(擬合過度),還無法達到真正的突破。至于這個scaling law的突破點在哪里?仍然還處于探索中。
除了數據原因之外,另一大原因是AI也不是萬能的,無論研發環節多么先進,藥物仍然需要進行人體臨床試驗。任何藥物研發的最后階段,都需要招募大量志愿者,這很需要時間,平均約10年。許多藥物需要花費數年時間才能進入這一階段,但仍然以失敗告終。
雖然有很多AI制藥公司都在加班加點地研發,但這些實驗室中的實驗和人體臨床試驗無法被縮短,所以第一批在人工智能幫助下設計的藥物,可能還需要幾年時間才能上市。
當然,雖然AI無法加快臨床試驗的進程,但它確實可以幫助制藥公司減少試錯成本,也就是減少在實驗室中測試無效藥物分子所花費的時間,讓有希望的候選藥物更快進入臨床試驗階段。而且,由于資金投入的減少,公司可能不會感到那么大的放棄壓力,而堅持想碰碰運氣。
如今正有越來越多的由AI輔助的藥物管線出現。根據智藥局統計,AI輔助的臨床管線已經從2022年的50條,增長到當前的102條,這還僅僅是統計的AI制藥公司的管線情況。
一級市場的資金也正在往該領域聚集。比如在上個月,生物技術領域最大的投資機構ARCH Venture Partners,做出了有史以來最大的一筆投資,單筆領投了2億美元,投資于AI+醫療創業公司Xaira。這家成立僅一年的創業公司,在種子輪就拿了10億美金,目標是利用 AI 來重塑藥物的研發、尋找治療疾病的新藥。
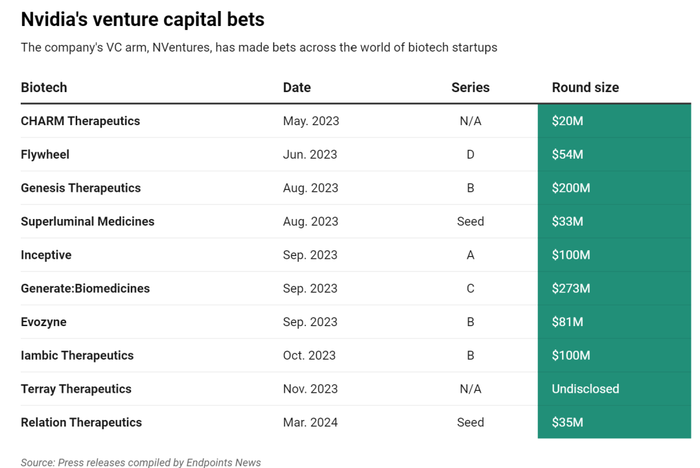
英偉達對Biotech的投資
當我們在討論AI制藥的未來時,它更像是一場漸進式的變革,而非突進式的變革。
這一輪AI熱潮與此前計算機輔助制藥最大的不同在于,算力和算法已經得到了顯著提升,相比之前已經產生了代際差異,這為藥物發現和設計提供了前所未有的精確度和效率。
由于數據問題,以及AI無法觸達的臨床試驗等耗時環節,至今仍未有獲批藥物是通過AI方式做出來的。但AI制藥的真正價值,可能不在于它能夠立即創造出超越現有藥物的奇跡,而在于作為一種工具,能夠系統性地解決以往難以解決的問題。這種系統性的解決方案,而不是偶發性的一兩次成功,如果能夠實現,將是對傳統制藥方法的一次重大突破,有可能帶來制藥行業的革命。
最新的研究里程碑也證明了這一點。華盛頓大學生物化學教授David Baker的研究團隊,首次利用AI技術從零開始設計出了一種新型抗體,將抗體療法推向了一個全新的高度。雖然尚未達到人類設計的頂尖水平,但已經證明了AI設計的蛋白質是可行的,這為未來的發展奠定了基礎。
最后,如果我們用一句話總結:“AI在大分子領域的潛力值得期待,但這個積極樂觀可能不是在一個2-3年的時間周期里,而是更長的、漸進式的發展周期里。”在古代,藥物發現純粹靠運氣;在近代,藥物發現依賴經驗和直覺;在未來,AI技術料將大大加速這一進程——這里提升10%,那里20%、30%,最終將所有這些改進相乘,速度和成功率就可以提高兩到三倍。
References:
1. EndPoints:Cash, chips and talent: Inside Nvidia's plan to dominate biotech's AI revolution
2. 國聯證券:醫療AI賦能醫藥產業新發展
3. The Economist:Big pharma is warming to the potential of AI
4. MIT Review:AI is dreaming up drugs that no one has ever seen. Now we’ve got to see if they work.
5. Reuters:Big Pharma bets on AI to speed up clinical trials