

文|烏鴉智能說
4月18日,Meta公司推出其開源大語言模型“Llama”(直譯是“羊駝”)系列的最新產品——Llama 3。此次發布共發布樂兩款開源Llama 3 8B與Llama 3 70B模型,供外部開發者免費使用。Llama 3的這兩個版本,也將很快登陸主要的云供應商。
根據Meta的說法,Llama 3 8B和Llama 3 70B是目前同體量下,性能最好的開源模型。強大的性能離不開龐大的訓練數據。據Meta透露,Llama 3是在由24000塊GPU組成的定制集群上,使用15萬億個token訓練的,數據規模幾乎是Llama 2的七倍。
Llama 3的推出,對開發者社區意義重大。Hugging Face聯創兼CEO Clément Delangue表示:“Llama 1和Llama 2現在已經衍生出了30,000個新模型。我迫不及待地想看到Llama 3將會給AI生態帶來怎樣的沖擊了。”
具體來說,Llama 3的主要亮點有:
? 在大量重要基準測試中均具有最先進性能;

? 基于超過15T token訓練,大小相當于Llama 2數據集的7倍還多;
? 訓練效率比Llama 2高3倍;
? 安全性有明顯進步,配備了Llama Guard 2、Code Shield等新一代的安全工具。
/ 01 / 性能全面領先的Llama 3
從發布的信息看,Llama 3公布了10項標準測試基準的表現,其中在與70億參數級的Mistral 7B模型和Google Gemma 7B模型對比中,Llama 3在9項標準測試基準上都有著更好的表現。
其中,包括MMLU(測試知識水平)、ARC(測試技能獲取)、DROP(測試對文本塊的推理能力)、GPQA(涉及生物、物理和化學的問題)、HumanEval(代碼生成測試)、GSM-8K(數學應用問題)、MATH(數學基準)、AGIEval(問題解決測試集)和BIG-Bench Hard(常識推理評估)。
從上圖不難看出,Llama 3 8B的成績在九項測試中領先同行,其中Gemma-7B模型于今年2月發布,一度被稱為全球最強開源大模型。Llama 3 70B則在MMLU、HumanEval和GSM-8K上戰勝了Gemini 1.5 Pro,同時在五項測試上全面優于Claude 3系列的中杯模型Sonnet。

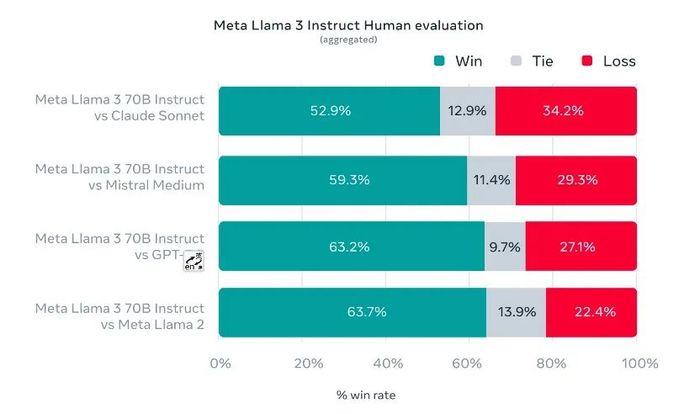
值得一提的是,Meta還組織了一個貼近用戶實際使用體驗的測試。根據Meta的說法,該測試集包含 1,800 個提示,涵蓋 12 個關鍵場景:尋求建議、頭腦風暴、分類、封閉式問答、編碼、創意寫作、提取、塑造角色/角色、開放式問答、推理、重寫和總結。
測試數據顯示,70B 版本的 Llama 3 在指令調優后,在對比 Claude Sonnet、Mistral Medium、GPT-3.5 和 Llama 2 的比賽中,其勝率分別達到了 52.9%、59.3%、63.2%、63.7%
Llama 3一經發布便引發了熱議。埃隆·馬斯克在楊立昆的X下面評論:“還不錯。”英偉達高級研究經理、具身智能負責人Jim Fan認為,即將推出的Llama 3-400B+模型將成為社區獲得GPT-4級別模型的重要里程碑。它將改變許多研究工作和草根初創公司的計算方式。
據Meta披露,Llama 3即將在亞馬遜云(AWS)、Databricks、谷歌云、Hugging Face、Kaggle、IBM WatsonX、微軟云Azure、NVIDIA NIM和Snowflake等多個平臺上推出。這一過程得到了AMD、AWS、戴爾、英特爾和英偉達等公司的硬件支持。
近期,Meta也將計劃推出Llama 3的新功能,包括更長的上下文窗口和更強大的性能,并將推出新的模型尺寸版本和公開Llama 3的研究論文。
/ 02 / 最強開源模型怎樣煉成?
Llama 3優越的性能,離不開Meta在訓練數據上的投入。根據Meta透露,Llama 3訓練數據規模高達15 萬億token,幾乎是Llama 2的七倍。
不僅如此,為了滿足多語種的需求,Llama 3超過 5%的預訓練數據集,由涵蓋 30 多種語言的高質量非英語數據組成。
為了確保 Llama 3 接受最高質量數據的訓練,Meta還開發、使用了啟發式過濾器、NSFW 過濾器、語義重復數據刪除方法和文本分類器來保證數據質量。
相比數據規模,數據來源更加令人關注。畢竟,此前Meta因訓練數據不足而產生焦慮,甚至一度爆出消息,在最近的一次高層管理會議中,Meta高管甚至還建議收購出版社 Simon & Schuster以采購包括史蒂芬金等知名作家作品在內的長篇小說為其AI模型提供訓練數據。
在此次發布Llama 3中,對于數據來源,Meta只說了“收集于公開來源”。不過根據外媒的說法,Llama 3使用的訓練數據,有很大一部分是AI合成的數據。有趣的是,兩個版本的數據庫日期還略微有點不同,8B版本截止日期為2023年3月,70B版本為2023年12月。
除了提高數據規模和質量外,Meta花了很多精力在優化訓練效率上,比如數據并行化、模型并行化和管道并行化。當16000個GPU集群上進行訓練時,Meta最高可實現每個GPU超過 400 TFLOPS的計算利用率。
同時,為了延長 GPU 的正常運行時間,Meta開發了一種先進的新訓練堆棧,可以自動執行錯誤檢測、處理和維護。
此外,Meta還極大地改進了硬件可靠性和靜默數據損壞檢測機制,并且開發了新的可擴展存儲系統,以減少檢查點和回滾的開銷。這些改進使總體有效培訓時間超過 95%。綜合起來,這些改進使Llama 3的訓練效率比Llama 2提高了約三倍。
為了優化Llama 3的聊天和編碼等使用場景,Meta 創新了其指令微調方法,結合了監督微調、拒絕采樣、近似策略優化和直接策略優化等技術。這些技術不僅提升了模型在復雜任務中的表現,還幫助模型在面對難解的推理問題時能生成正確的解答路徑。
在外界關注的安全性上,Meta采用了一種新的系統級方法來負責任地開發和部署Llama 3。他們將Llama 3視為更廣泛系統的一部分,讓開發人員能夠完全掌握模型的主導權。
指令微調在確保模型的安全性方面也發揮著重要作用。Meta的指令微調模型已經通過內部和外部的努力進行了安全紅隊(測試)。Meta的紅隊方法利用人類專家和自動化方法來生成對抗性提示,試圖引發有問題的響應。比如,他們進行了全面的測試,來評估與化學、生物、網絡安全和其他風險領域相關的濫用風險。
通過以上的種種努力,才最終打造了最強開源大模型Llama 3。據國外媒體道理,Meta希望Llama3能趕上OpenAI的GPT-4。
由此可見,開源和閉源的爭論遠遠沒有到停下的時候。如今,Meta用Llama 3給出自己的回應,接下來就看OpenAI如何應對了?