
文|新火種 文子
編輯|小迪
如果全世界只有一家公司能趕超OpenAI,那谷歌應該是第一。
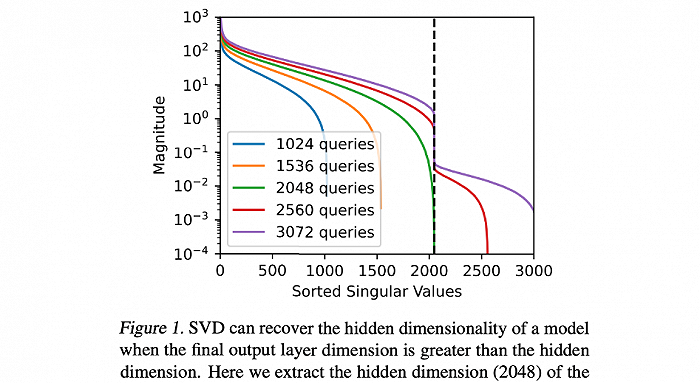
最近,谷歌重磅發布了一篇論文報告,里面提出了一種名為“模型竊取”的技術。通過模型竊取技術,谷歌成功破解了ChatGPT基礎模型Ada和Babbage的投影矩陣,甚至連內部隱藏維度的關鍵信息也是直接破獲,分別是1024和2048。
這一發現猶如一記重磅炸彈,在AI界引發了強烈的震動。誰也沒想到,號稱“CloseAI”的OpenAI竟然也會被竊取模型機密的一天。
更恐怖的是,這種模型竊取技術還非常簡單。只要你擁有ChatGPT這類封閉大模型的API,就可以通過API接口,發送不到2000次經過精心設計好的查詢,然后去分析它生成的輸出,就可以逐步推斷出模型的內部結構和參數。
雖然這種方法不能完全復制原始模型,但已經足以竊取它的部分能力。而且這種攻擊非常高效,不需要用太多的成本,就可以拿到模型的關鍵信息。

按照谷歌的調用次數來看,僅僅只需要不到20美金(約合150元人民幣)的成本,就可以完成模型竊取的操作,并且這種方法同樣適用于GPT-3.5和GPT-4。
換句話說,就是不費吹灰之力獲得了一個大模型理解自然語言的能力,還能用來構建一個性能相近的“山寨版”模型,既省事又省錢。
反觀OpenAI,被競爭對手低價破解模型機密,真的坐得住嗎?坐不住。截至目前,OpenAI已經修改了模型API,有心人想復現谷歌的操作是不可能了。
值得一提的是,谷歌研究團隊中就有一位OpenAI研究員。不過作為正經安全研究,他們在提取模型最后一層參數之前就已經征得OpenAI同意,而在攻擊完成后,也刪除了所有相關數據。
但不管怎么說,谷歌的實驗足以證明一點,哪怕OpenAI緊閉大門也并不保險。
大模型全面受挫,敲響開閉源警鐘
既然封閉的大模型都無法幸免,開源的大模型又會如何呢?
基于這一點,谷歌針對不同規模和結構的開源模型進行了一系列實驗,比如GPT-2的不同版本和LLaMA系列模型。
要知道,GPT-2是一個開源的預訓練語言模型,分為小型模型(117M)和大型模型(345M)兩種。而在對GPT-2的攻擊中,谷歌通過分析模型的最終隱藏激活向量并執行SVD發現,盡管GPT-2小型模型理論上具有768個隱藏單元,但實際上只有757個有效的隱藏單元在起作用。

這也就意味著GPT-2可能在實際使用中,并沒有充分利用其設計的全部能力,或者在訓練過程中某些維度的重要性不如其他維度。
此外,谷歌還研究了模型中的一種叫做“歸一化層”的東西對于攻擊的影響。一般來說,歸一化層的作用是讓訓練更加穩定,從而提升模型的表現。然而谷歌發現,即使模型加入了歸一化層,攻擊的效果也并沒有減弱。這說明即使考慮了現代深度學習模型中常見的復雜結構,攻擊方法也依然有效。
為了進一步驗證攻擊的范圍,谷歌還將目光瞄向更大、更復雜的LLaMA模型。它是由Meta發布的大語言系列模型,完整的名字是Large Language Model Meta AI,可以說LLaMA是目前全球最活躍的AI開源社區。
通過對LLaMA系列模型進行攻擊,谷歌成功地從這些模型中提取了嵌入投影層的維度信息。值得注意的是,即使在這些模型采用先進的技術,如混合精度訓練和量化,攻擊依然能夠成功,這表明攻擊方法的普適性和魯棒性。
可以說,谷歌給閉源和開源兩大領域同時敲響了一記警鐘。
AI三巨頭對線,2024誰輸誰贏?
從嚴格意義上來講,OpenAI、谷歌、Meta就是爭奪AGI圣杯的三大巨頭。
其中,Meta和OpenAI完全相反,前者走的是開源路線,而后者主要打造閉源模型。但谷歌和他們完全不一樣,閉源與開源雙線作戰,閉源對抗OpenAI,開源對抗Meta。
在人工智能領域里,谷歌可以算是開源大模型的鼻祖。今天幾乎所有的大語言模型,都是基于谷歌在2017年發布的Transformer論文,這篇論文顛覆了整個自然語言處理領域的研究范式。而市面上最早的一批開源AI模型,也是谷歌率先發布的BERT和T5。

然而,隨著OpenAI在2022年底發布閉源模型ChatGPT,谷歌也開始調整其策略,逐漸轉向閉源模型。這一轉變使得開源大模型的領導地位被Meta的LLaMA所取代,后來又有法國的開源大模型公司Mistra AI走紅,尤其是其MoE模型備受行業追捧。
直到谷歌今年再次發布開源大模型Gemma,已經比Meta的LLaMA整整晚了一年。
很顯然,Gemma這次的發布標志著谷歌在大模型戰略上的巨大轉變,這一舉動意味著谷歌開始兼顧開源和閉源的新策略,而其背后的目的也是顯而易見。
眾所周知,當前大模型領域的競爭已經形成了一種錯綜復雜的打壓鏈格局。其中OpenAI牢牢站在鏈條頂端,而它所打壓的恰恰是那些有潛力追趕上它的競爭對手,比如谷歌和Anthropic。而Mistral作為一股新興力量,估計也正在被列入其中。
如果非要排列一個打壓鏈條,那可以歸結為:OpenAI→Google &Anthropic &Mistral→ Meta→其它大模型公司。
可以說,無論在閉源還是開源領域,谷歌都沒能確立絕對的領先地位。
所以這也不難理解,為什么有專業人士會認為,谷歌選擇在此時重返開源賽場,是被迫的。谷歌之所以開源主打的是性能最強大的小規模模型,就是希望腳踢Meta和Mistral;而閉源主打的是規模大的效果最好的大模型,就是為了希望盡快追上OpenAI。
但無論如何,在未來的對壘格局里,谷歌已經先發制人,成功將壓力給到OpenAI和Meta。
這一次,關鍵在于OpenAI和Meta該如何應對。