
界面新聞記者 | 李京亞
界面新聞編輯 | 宋佳楠
馬斯克的Neuralink想把芯片植入完全健康的人類大腦,但一些大模型公司想最先“征服”智能手機。
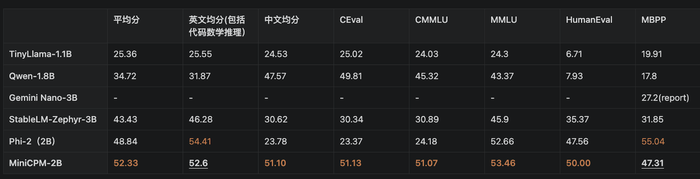
近日,國內大語言模型創業公司面壁智能推出了只有20億參數量級的端側語言模型面壁MiniCPM,希望“以小博大”。參數量級是衡量模型規模和潛在學習能力的一項關鍵指標。
雖然目前大模型評測難以形成統一標準,且缺少公開的提示詞和測試代碼,但面壁智能研究團隊發表論文稱,其小模型MiniCPM的性能超越或與市面上大部分70億規模大模型持平,超越了部分百億參數以上大模型。
這與全行業正在給予小模型的高關注度相吻合,尤其是小模型在智能手機、嵌入式系統等邊緣設備上展現出天然應用優勢之后。
面壁智能聯合創始人劉知遠表示,在Mistral-6B的同一模型水平下,面壁智能團隊的模型參數量是最小的。這或許意味著模型的效率被提升到了最高水平。
邊緣設備通常只有有限的計算能力和存儲空間,無法有效地運行大型語言模型。當手機廠商僅靠硬件難以實現差異化時,他們希望把大模型塞進手機,成為移動設備的又一賣點。更重要的是,這些大模型主要依托于云計算,例如OpenAI的ChatGPT使用了微軟的云服務。

為擺脫對OpenAI的依賴,去年6月,微軟便發布論文證明,13億參數的模型也能具備非常良好的性能,此后這家公司集中開發了Phi系列小模型。同樣看到小模型在降本和提高業務效益方面潛力的還有谷歌和Stability AI,他們紛紛在小模型上發力。
急需找到新增長曲線的手機廠商如華為、OPPO和vivo,已經在去年下半年開始部署端側模型,只是模型適配尺寸暫不統一,如榮耀是把端側模型參數局限在70億之上,小米則是13億。
據面壁智能團隊透露,MiniCPM已經跑通了國際主流手機品牌和終端CPU芯片,目前正與多家終端廠商溝通,探討將MiniCPM落地的各種可能。該團隊還表示,將完全開源MiniCPM-2B的模型參數供學術研究和有限商用。

更小的參數意味著更低的部署門檻和使用成本,某種程度上有助于解決云側模型耗能、算力等成本居高不下的問題。
據面壁智能CEO李大海介紹,MiniCPM的單個模型成本較低,原因是足夠小的參數能夠實現推理成本的斷崖式下跌,甚至可以實現CPU推理,只需一臺機器持續參數訓練,一張顯卡進行參數微調,同時也有持續改進的成本空間。
不過,業界對大模型端側部署還有些重要問題尚未達成共識,比如手機上跑大模型到底有什么用?到底能跑多大的模型?
為探究大模型在手機上的真實使用場景,阿里前副總裁、人工智能科學家賈揚清的整體感受是,做信息提取跟信息摘要效果較好,而涉及創作、展示創造的東西,則需要更大的模型承載,“大家會覺得在云端跑更好”。
對前述問題,力推端側模型的面壁智能也不能給出明確答案。在李大海看來,賈揚清的觀點屬于某個具體時點看到的特定現象,但伴隨著大模型的快速發展,端側模型能力邊界有了極大提升,這些論斷就有可能不成立。
“我們不會對手機大模型的應用場景設限,因為其本身就是通用人工智能。”清華大學長聘副教授、面壁智能聯合創始人劉知遠表示,在為系統提供穩定接口之后,會解鎖很多新玩法,比如訂餐與旅游。像蘋果Siri能做的事情,都可以作為端側大語言模型驅動的應用。
他判斷端側大模型有極大可用潛力,因為其不像云端模型一樣要跟隱私數據進行交互,可以高度保護個人隱私。未來大模型會是云端共存、云端協同的模式,而他們希望探索模型性能的天花板。
這家創立于2022年的公司,創始成員全部來自清華大學自然語言處理NLP實驗室。
早在2019年,已經在科學界聲名鵲起的劉知遠決定把清華NLP實驗室的研究方向從傳統NLP命題中撤出,全面圍繞大模型領域展開。2020年底,劉知遠、曾國洋(現任面壁智能CTO)帶領的面壁早期核心團隊發布了首個中文大語言模型CPM-1,三年時間內陸續發布了CPM-2(110億參數)、CPM-3、CPM-Ant、CPM-Bee等模型。
后來公司開始向商業化轉型,并以實現AGI(通用人工智能)為長遠目標。“AGI的實現需要我們做什么,我們就做什么。”劉知遠稱。
去年4月,知乎官宣了與面壁智能的合作。6月,知乎CTO李大海出任面壁智能董事和CEO,開始全面負責后者的戰略發展和日常管理。
同在4月,面壁智能完成了由知乎獨家投資的千萬人民幣級別天使輪融資,這是其迄今為止唯一一輪融資。在國內基礎大模型領域競爭中,這家公司需要面對Minimax、百川智能、智譜AI、零一萬物和月之暗面等實力強勁的對手。
當下,面壁智能不僅需要證明自己的技術,還需要證明技術給產品帶來的好處,因為大模型投資人正在密切關注商業變現。
自去年6月開始,國內AIGC領域整體投融資趨冷,而在硅谷,一大批AIGC新興初創開始死去。
日前,AI搜索引擎新貴Perplexity CEO表示,AI創業公司應該先做產品,后做模型,成為一個擁有十萬用戶的套殼產品比擁有自有模型卻沒有用戶更有意義。目前,這家公司正在跟谷歌叫板。
李大海對這一觀點部分認同。他告訴界面新聞,大模型公司有兩種思路“可行”:產品能力更強的公司,模型一側可以先置空;模型能力更強的,可以后面再做商業化。大模型既是技術,也是產品,關鍵是要盡快形成數據飛輪,建立模型跟應用的閉環。
據他透露,面壁智能的商業收入以金融、營銷領域的大型企業客戶為主,端側大模型的商業模式則還在探索之中。
不過,據界面新聞記者了解,華為、OPPO、vivo等主流手機廠商都在自研端側大模型。像榮耀與百度文心一言盡管有合作,也多是在前者自有端側模型上提供輔助支持,完全使用外部端側大模型的案例仍然很少。
而且在現實中,大模型頭部廠商想在短時間內做好端側應用并不容易。
一位大語言模型產品經理表示,大模型頭部廠商有能力用較低成本在端側模型上取得更好效果,但在挖掘場景方面欠缺經驗。具備大模型技術積累的手機廠商一樣有機會做出好的應用。
這也意味著,在徹底解決隱私安全等一系列問題之前,面壁智能想要說服手機廠商大范圍使用其產品并不容易。