
文|新莓daybreak 史圣園
編輯|翟文婷
百度高調發布文心大模型4.0,再次將人們的目光聚焦在生成式AI。
李彥宏的說法是,與GPT4相比,文心 4.0的綜合水平已經毫不遜色,理解、生成、邏輯和記憶四大能力,都有明顯提升。
基礎模型的能力決定著AI 原生應用的可能性。
AI 時代,搭建應用的技術成本顯著降低,最重要的還是找到「場景」。未來將有大量的大模型應用井噴,已成為行業內、投資圈的共識。問題在于,什么時候才能產生真正意義上的AI爆款應用?
百度的解題方法是,一方面押注自己,將既有產品線用 AI重構;另一方面也將籌碼均勻分布到「生態」。百度智能云應用商店、靈境插件平臺,試圖搭建 AI 時代的 App Store,擴大命中「殺手級應用」的概率。
問題是,百度如何才能避免讓這種熱情淪為一廂情愿呢?
畢竟現實是,C端用戶使用AI應用的頻次并不高,找不到打開AI的正確方式;B端客戶采買的決策鏈路復雜漫長,同時擔心數據安全。這個行業癥結,百度是否有正確解法?
喊話 GPT 4
學界普遍認為,參數規模越大,模型的通用能力越強。
此次發布會上,李彥宏沒有提及文心大模型 4.0 的參數規模,而是著重展現了貼合生活場景的模型能力。據《晚點 LatePost》報道,該版本參數規模或達到萬億級別。
李彥宏依次展示了文心大模型的四大能力:
·理解能力,他用公積金異地貸款為例,展示文心 4.0 對于前后亂序、表述模糊、潛臺詞洞察的能力。
·生成能力,讓大模型根據需求,生成一整套汽車的營銷素材,包括文案、海報、視頻等多模態內容。
·邏輯能力,舉例的場景是家長輔導功課,文心一言給孩子講解數學題,包括解題思路、計算過程,以及知識點的延伸。
·記憶能力則是通過小說創作的案例,不斷補充人物關系、戲劇沖突等細節,展示大模型在多輪對話中的記憶力。
值得一提的是,這四個場景均跟生活和工作中的「生產力」相關,強調切實的信息價值,弱化了休閑娛樂場景的陪伴、互動能力。看起來,文心一言的定位更像是一個「萬金油」助手。
主動發出這樣的信號,或許說明百度對模型能力有著更高的要求,想要積累更多的高質量用戶數據。大模型的幻覺、行業知識的缺乏,是其廣泛落地的最大障礙。
娛樂場景的閑聊,雖然門檻低、有趣、易傳播,更容易積累大量的語料,單個用戶就能在一天中聊幾百個來回,但這些數據對底層模型的知識提升較為有限。而行業用戶所提出的問題、給出的反饋,才能真的讓大模型更懂業務場景。
新莓 daybreak 選取了一個注冊會計師考試題目,來實際測試文心 4.0和 GPT-4 目前的能力。該題目的計算過程,涉及 4 個解題步驟。
很遺憾,中外兩款大模型都未能正確回答,但均給出了解題思路。目前線上版本的文心一言依靠文心3.5模型,在第一步就出現了計算錯誤;而文心 4.0 和GPT-4 均是在第三步出現了計算錯誤。由此看來,各家大模型的推理能力均有待加強。

CPA考題,各家大模型均計算錯誤
當我們提示「計算步驟中是否出現數據錯誤」時,GPT-4 修正了數據錯誤,并給出了正確回答;而文心3.5、4.0 均開啟了另一個話題,試圖說明「數據計算出現錯誤」是什么原因,雖然文心4.0的解釋更翔實,但它并未能理解這句指示的真正意圖。GPT-4的上下文記憶和理解能力,目前略勝一籌。

GPT4 在用戶提示下修正了錯誤
以上測試,均是在未經微調的通用應用上進行的測試。在實際應用時,往往需要用業務數據對模型進行微調;然而,通用大模型在某個特定任務上的能力上升,可能會伴隨著其他場景上的能力下降。因此,針對不同的領域任務,推出不同的微調接口,對于實際應用尤為重要。
一些企業客戶已經開始接入文心4.0體驗測試,某金融機構的IT部門告訴新莓daybreak,4.0版本的知識問答能力比之前有較大的提升。
AI重構應用
「沒有構建于基礎模型之上的豐富的 AI 原生應用,大模型就一文不值。」李彥宏說。他認為,AI 原生應用就是基于大模型的理解、生成、邏輯和記憶能力開發出來的應用。
此前,李彥宏曾從更感性的角度給出 AI 原生應用的定義。除了以上四點技術能力外,還需要滿足兩個條件:能用自然語言交互、每個功能不超過兩級菜單。
換言之,AI 原生應用,應該是簡單、直覺、輕量的。
改革先從自家的產品做起,百度搜索、網盤、文庫、地圖、智能辦公(如流)、輸入法等全線產品,都進行了 AI 化改造。
先來看搜索。百度曾靠搜索起家,后來知乎、微博、小紅書、B站,紛紛搶占了用戶的搜索時間。
早在2年前,抖音的搜索月活達5.5億次+,快手搜索月活達3億次+,單日視頻搜索量達2.5億次+;截至2023年2月,小紅書日均搜索查詢量達3億次。比起各類社交媒體上的專業領域KOL,百家號、貼吧構筑的內容池,顯得吸引力不足。另一方面,僅能命中文本關鍵詞的搜索形式,無法很好地搜索圖片、視頻等內容,已經無法滿足多元的搜索需求。
這一次,百度搜索想借助 AI 變得更懂用戶。李彥宏介紹,「新搜索不再是給你一堆鏈接,而是通過大模型去理解,生成一個最好的答案。」他將新搜索的特點歸納為「極致滿足、推薦激發、多輪交互」。
用大白話說,搜索引擎不再只是按照你輸入的關鍵詞搜內容,而是跟你聊天,并將結果整理成更易懂、易用的通俗語言。如果「對話」是搜索未來的產品形態,那么被顛覆的不僅是用戶體驗,還有搜索引擎的商業模式。
AI 搜索,不再是搬運內容,而是在創造內容。
如果當 AI 的創造包含廣告的成分,且不加以區分,那么用戶將無法信任搜索的結果。如果限制商業行為對AI回復的干擾,那么競價排名的廣告收入勢必會受影響。目前,線上使用的百度搜索仍然是老版本,只是多了一個喚起 AI 助手的入口。
百度文庫、百度網盤也紛紛在各自的界面上加入了 AI 助手。網盤助手和文庫助手都可以幫助用戶總結內容、提煉要點。功能都是好功能,但放在一起,不免讓人覺得,各條產品線的 AI 助手大同小異。
讓人眼前一亮的是 AI 版輸入法。百度輸入法的 AI 功能叫「超會寫」,主打「讓你社交溝通不再精神內耗」,洞察到了一個剛需、高頻、且對生成文案容錯率較高的場景。但目前,點擊輸入欄的按鈕喚起AI的交互,還是略顯刻意。AI功能和輸入法的融合,微信輸入法更潤物細無聲,將輸入本身變成召喚術:在輸入文字后,自動聯想到優化表達、喚起音樂等貼合場景的需求。
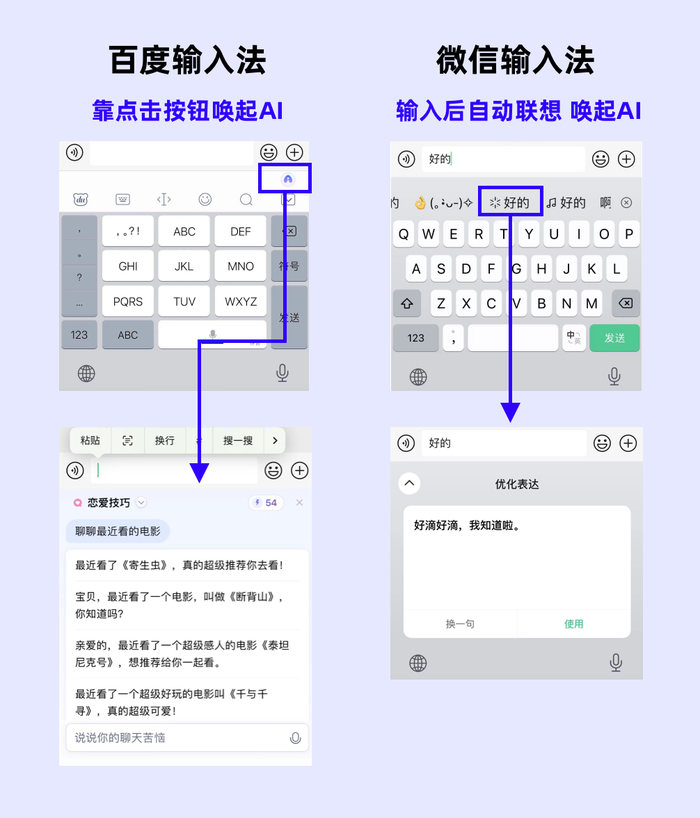
微信輸入法的AI喚醒方式更加自然
百度 AI 原生應用商店也一并上線,截止 10 月 22 日,共有 55 款應用。生態中的智能應用,集中在智能客服、AI輔助寫作、專業知識問答等幾個場景,和百度自有產品線的應用場景高度重合,但多了一些行業屬性。
如何先用起來
阻礙 B 端用戶應用大模型的,主要是成本和預期的問題。無論規模,企業們都非常看重數據的私密性。
Cathy 是一家大模型公司的解決方案工程師,她說,即使是云端私有化的方式,一些客戶還是感到不安。「客戶最開始試驗的,都是一些對數據安全要求不太嚴格的功能。但如果后續想要一些深度功能,就紛紛都要求私有化了。」
但如果要將大模型做私有化部署,價格往往需要幾千萬元,整個決策鏈路就要被無限拉長。
David 所在的創業科技公司長期服務企業客戶。不僅是他們,客戶公司的部門領導也更喜歡短平快、立竿見影的小項目,讓自己的部門先做起來。「大型機構的招投標,如果從部門上升到整個公司層面,就會變得極其復雜。」
「客戶的需求都比較理想化,他們都希望用稍微小一點的模型,最好可以私有化部署,然后還能達到很好的效果。」David 說,經過他們測試,如果企業內部的數據質量足夠高,在 6B、13B 的小參數模型上進行特定任務訓練,也能達到相對理想的效果。
David還補充道,「不僅僅是私有化的成本,單次推理的成本也會更低,速度還會更快。我的親身體會是,小參數的模型,客戶接受起來更容易一些。」
而對于大多數 C 端用戶來說,真正使用 AI 的頻次并不高。一些 AI 應用的定價從側面證實,用戶訂閱 AI 服務頗有點沖動消費的意味。「為 AI 付費,感覺像是辦了個健身房的年卡會員,是在消費一種『我會更加高效』的感覺。」
海外用戶量較大的兩款文檔處理類 AI 工具,ChatPDF 和 PDF.ai,都將月度會員的權益放大到幾乎「無限次使用」,再收取十幾美元的價格。
這兩款產品都出自個人開發者之手,他們沒有賠本賺吆喝的必要。從實際使用情況來看,很少有用戶高頻使用,十幾美元就足夠覆蓋用戶消耗的成本。用戶使用程度不夠深入,或許也說明,AI 現有的能力,并沒有達到用戶的期待。
但也不是絕對的。程序員是為數不多認真在使用 AI 產品的人群。
GitHub Copilot 的售價也是每月10美元,華爾街日報卻報道稱,平均每位付費用戶每月給微軟帶來了20 美元的虧損。從另一個角度看,微軟每月用 20 美元的價格,雇傭了一個認真的用戶,提供高質量的數據幫他們訓練 AI。
人人都知道下一個機會在應用層,可是找準場景、利用 AI 絲滑地升級現有產品,又談何容易。
企業用戶還在擔心數據安全,大量個人用戶找不到 AI 的正確打開方式。大模型想要兌現商業價值,似乎長路漫漫。
而百度的搶跑似乎在告訴我們,快人一步,至少意味著更多空間和可能。