
文|阿爾法工場
當下的大模型賽場,隨著最初的熱潮褪去,不少VC和投資人對大模型已經進入了一個冷靜期,其投資標準,也變得理性、嚴謹了許多。
既然如此,那么這一階段能得到明星資本青睞的團隊,都具有哪些特征呢?
如前段時間,突然發布自身產品的神秘創業公司——月之暗面Moonshot AI,就給我們提供了一個參考。
在自身的大模型 Kimi Chat發布前,很少有人會想到,這個創始人僅31歲,且沒有任何產品發布的AI初創企業,會獲得紅杉中國和真格基金等 VC 的投資,并被The Information 選為五家「中國 OpenAI」的創業公司之一。
那么,對國內大模型而言,月之暗面的入局,究竟是又一場講故事的炒作,還是一匹赫然出世的黑馬?
01 VC們的考慮
現階段,要拿捏一個AI初創企業的含金量,除了企業公開展示的信息外,從VC們的角度倒推回去,分析其投資的理由,也是一種值得借鑒的思路。
以投資了月之暗面的明星資本紅杉中國為例,目前紅杉中國在AI領域已經已投資了近 30 家企業,但其真正的核心標準只有兩個:1、有使用場景,解決實際問題;2、系統能夠持續不斷獲得有用的數據自我學習來提升處理能力。
在第一條標準上,紅衫中國對AI企業的篩選,有著與國內大多數VC不同的洞見。
當前,AI 投資大多集中在 B 端,因為相較于C端,B端的行業垂直類大模型更好找到應用場景。
然而,紅衫中國卻認為,垂直行業背景不是必備條件,而對行業痛點的深刻洞察,則是更為重要的因素。
比如摩拜創始人不是做自行車的,但是她發現了實實在在的需求,并且意識到在這個過程中 AI 能夠發揮價值。
按照這樣的思路,來看月之暗面的情況,我們就會理解紅衫中國投資的理由。
在月之暗面發布的大模型Kimi Chat,是首個支持輸入 20 萬漢字的智能助手產品。這一上下文長度,是目前最高的 Claude 2-100k(約 8 萬字)的 2.5 倍,GPT-4-32k(約 2.5 萬字)的 8 倍。
超長的文本輸入,意味著什么?
在Kimi Chat發布前,大模型落地的一個最大阻礙或瓶頸,正是輸入長度的限制。
由于長度所限,任何需要進行長篇分析或持續對話的場景,現有的大模型都難以勝任。
例如,在法律行業中,有時從業者需要處理大量的長文本,例如法律文件、合同、判決書、案例等,而在媒體行業中,編輯或撰稿人,也需要對大量的文章、新聞、報道進行分析閱讀。
誠然,面對輸入長度的限制,人們可以用“分段發送”這種投機取巧的方式規避,然而,由于長度所限,在達到字數限制后,大模型仍然必須對每段內容重新開始分析。
而這種不斷“從頭開始”的情況,也使大模型難以形成一套連貫的、有深度的見解。
這樣的情況,就像是一個原始人,雖然學會了寫字,但卻因文字載體(只能刻在石頭上)所限,無法保存更多的信息,積累更多的智慧,于是文明便無法長遠地發展。
而大模型要想擺脫這樣的“原始階段”,向更廣闊的場景擴展,文本長度的限制是一定要突破的。
也正因如此,抓住了“長度限制”這一痛點的月之暗面,才會如此得到紅衫中國的重視。
然而,除了具體的場景、技術之外,“人”的因素,在大模型創業過程中同樣不可忽視。
02 技術天才的前路
當下,幾乎每個AI初創企業都想成為OpenAI,但又有多少團隊具備那樣的人才配備,以及能讓其充分發揮自身才干的土壤呢?
從表面上看,在目前的大模型創業熱潮中,名校畢業、大廠經驗、濃厚的技術基因,似乎已經成了一種“標配”
月之暗面的情況也是如此。
其創始人楊植麟,不僅出身清華,深造于卡內基梅隆大學,后來又效力于谷歌大腦研究院和Meta(Facebook)人工智能研究院,并且還曾與圖靈獎得主楊力昆(Yann LeCun)合作發表論文。
同樣的,身為團隊第二大股東的周昕宇,也是楊植麟清華大學計算機科學與技術系的同學;
而第三大股東吳育昕,畢業于清華大學與卡耐基梅隆大學,曾獲2018年歐洲計算機視覺會議(ECCV)最佳論文提名。同時也是Meta(Facebook)人工智能實驗室FAIR團隊的一員。
從人員構成上看,這是一個技術基因頗為濃厚的團隊。
然而,在當下的國內大模型賽場上,明星般的技術人才很多,可真正做出突出成就的,卻仍是鳳毛麟角。
原因何在?
從OpenAI、Midjorney等成功團隊的案例中,我們至少可以總結出兩點:1、團隊對自身“獨立性”的堅持;2、創始人的視野、經驗是否開闊;
關于第一點,就國內的情況而言,盡管“技術天才”創業的案例已不在少數,但其中相當一部分團隊,由于缺乏股權或經濟上的獨立性,最終被收購、控股,如之前被光年之外收購的一流科技就是這樣的例子。
而相較之下,OpenAI、Midjorney在融資、股權問題上,則有著更為獨立的自主權。
身為非盈利性組織的OpenAI,不用總是將股東的意志放在第一位;而Midjorney的創始David Holz,更是憑借著自身的名氣與人脈,在不融資的情況下就集齊了相應的資源、人才。
凡此種種,都使其更易于堅持自身獨立的研究方向。
而在這方面,根據天眼查App信息顯示,月之暗面由楊植麟持股78.97%,擁有絕對控制權。

除了對“獨立性”的堅持外,創始人的視野和實踐經驗,也成了大模型團隊成敗的另一大因素。
因為技術型團隊,雖然對研究有著純粹的熱忱,但有時候,這樣的執著卻會“劍走偏鋒”,陷入一種誤入歧途的窘境。
在當下AI的發展方向中,存在著許多不同的路徑,有些是有前景的、靠譜的,有些則是需要排除的“錯誤選項。”
而唯有與國外一流的高校、機構和企業進行廣泛交流,并親自參與實踐,才能從中得出正確的、具有前瞻性的判斷。

說回到月之暗面,在視野與實踐經驗方面,楊植麟曾效力于谷歌大腦研究院和Meta(Facebook)人工智能研究院,是Transformer-XL和XLNet的第一作者。
其中,XLNet模型曾在18項自然語言任務中取得了好于谷歌BERT的效果,是當時NLP領域熱門的國際前沿模型之一。
這樣開闊和前沿的履歷,確保了作為創始人的楊植麟,在技術方向的把握上,保持了與國際一線人才相近的水準。
03 “局部勝利”的含金量
在目前月之暗面公布的信息中,其最為人稱道的一點,就是推出了首個支持輸入20萬漢字的大模型Moonshot,以及搭載該模型的智能助手產品Kimi Chat。其文本長度是GPT-4-32k(約 2.5 萬字)的 8 倍。
可以說,這是國內在局部領域對GPT-4等先進模型取得的又一場“勝利”。
為什么說“又”呢?
因為此前已經有不只一個國產大模型,宣稱自己在某些方面“超越”了GPT-4。
9月,學術界當紅開源評測榜單C-Eval最新一期排行榜中,云天勵飛的大模型“云天書”排在第一,而GPT-4僅名列第十。
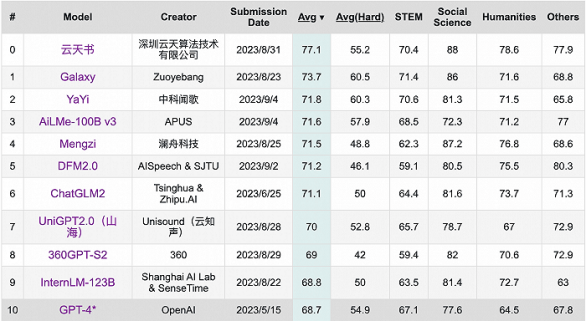
之所以會出現這樣詭異的現象,是由于部分國產大模型,學會了一些別樣的“應試技巧”(例如將測評的答案摳下來訓練),才造成了如此奇觀。
其實,從OpenAI的經驗來看,一種真正的技術上的“局部勝利”,應該是對AI某一領域天花板的突破,而不是呈一時的數據英雄。
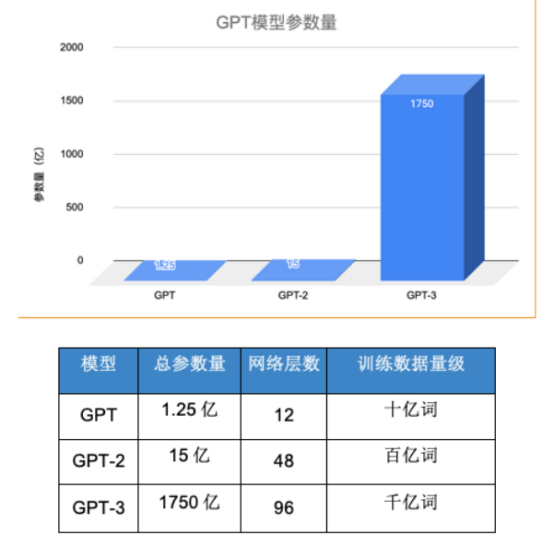
這也是為什么,當年GPT-1被谷歌的BERT打得完敗,且測評、數據紛紛拉胯的情況下,OpenAI仍然選擇大模型,而非小模型的原因。
畢竟,小模型在專業任務上表現雖強,但只要參數無法提升,更強的智能就無法涌現。
同樣地,目前月之暗面推出的Moonshot,同樣可以看作是對大模型某一“天花板”的突破。
因為在長文本方面,也存在文本長短、注意力和算力類似的“不可能三角”。
這表現為,文本越長,越難聚集充分注意力,難以完整消化;注意力限制下,短文本無法完整解讀復雜信息;處理長文本需要大量算力,提高成本。
在這樣的不可能三角中,自注意力機制的計算量會隨著上下文長度的增加呈平方級增長,比如上下文增加32倍時,計算量實際會增長1000倍。
而計算量的提升,就意味著就不得不消耗更多的算力,而這無疑意味著更高的模型部署成本。
有鑒于此,唯有以長文本技術為突破,人們才能在其通用模型基礎上去裂變出N個應用。
現階段,長文本的“不可能三角”困境或許暫時還無解,但正因如此,攻破這樣的“天花板”才真正有其意義和價值。
而所謂中國的OpenAI,或許正是誕生于對這一個個“天花板”的攻克中。