
文|新莓daybreak 史圣園
編輯|翟文婷
騰訊混元大模型終于亮相。
用騰訊自己的話說,之前是「不急于把半成品拿出來展示」。但此次發布,他們卻也坦陳,目前「只是可用、可實踐」。
早在 3月,百度文心一言就啟動了內測邀請;4月,阿里通義千問緊隨其后。連姍姍來遲的字節,也在 8 月 17 日對外測試 AI 對話產品「豆包」。
在「百模大戰」中,先發優勢重要嗎?
似乎沒那么重要。大模型是一種非常標準化的產品,無論是個人、企業還是開發者,都可通過 API 即可接入,切換模型的成本相當低。最終,還是產品的效果和體驗決定一切。
但也有點作用。用戶真實的提問,是最寶貴的數據資產。先跑起來,就能積累更多數據,幫助大模型在充滿噪音和歧義的真實場景中訓練、學習、增強能力。
8 家首批通過《生成式人工智能服務管理暫行辦法》的大模型產品,已經陸續開放注冊,普通用戶終于可以上手體驗了。不過,聊上幾輪,就會有種大模型產品「還沒成年就出來打工掙錢」的感覺 —— 閑聊可以,但不能細究。
這也不免讓人擔心,生成結果的不穩定性,會成為實際部署的掣肘,且優化周期較為漫長。
真正能留在牌桌的大模型玩家,一定是少數。
同質化競爭?
從各個廠商公布的大模型產品和解決方案來看,同質化的情況比較嚴重。
在 toB 辦公場景,主要聚焦在文檔和會議場景,充當創作助理、會議秘書、設計助手的角色;toC 個人場景,打出的牌也都是情感陪伴、生活向科普(菜譜、旅游策劃)。
目前,百度文心、字節豆包、智譜 AI、百川智能均全面開放注冊使用;中科院紫東太初正在維護中,商湯日日新需要邀請碼,MiniMax 僅面向開發者,上海人工智能實驗室的書生通用大模型還未開放注冊。
此外,訊飛星火大模型也開放了全面注冊,騰訊混元大模型暫時還是邀請制,需要申請并排隊。
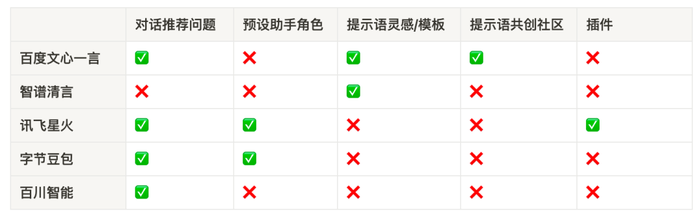
開放注冊的 5 款產品都是 chatbot 形式,也都加入了不同程度的提示語引導、使用場景提示。有的是在對話中推薦問題,有的預設了助手角色。有的做得更深入一些,制作了提示語模板、社區或插件,能隱隱約約看到搭建生態的野心,向用戶和開發者創造力借智,但目前都處于較為初期的階段。
但用戶感知上的相似,并不等于業務邏輯的相似。
各家大模型廠商無一例外,都想借力公司既有業務,進行差異化競爭。
百度是最強調「生態」的大廠,結合最深的業務場景也是「搜索」。在文心一言首頁的顯著位置,就放置了插件市場入駐申請的鏈接。在連接開發者和創業者上,百度也尤為積極,搶先舉辦了文心杯創業比賽。而在百度搜索引擎中,AI對話助手也已經上線,并開放使用。

阿里通義千問最先落地的場景是釘釘,釘釘總裁葉軍曾表示,「要用大模型把釘釘重做一遍」。
騰訊發布混元大模型時,也同步表示,騰訊云、騰訊廣告、騰訊游戲、騰訊會議等 50 余個業務和產品均已接入。
而訊飛在機器語音識別領域掌握 9 種方言,這讓星火大模型在接納語音數據時占據了絕對優勢。此外,訊飛的學習機等教育硬件,讓星火大模型與教育場景結合有著天然優勢。
「很多都會迅速消失」
除了技術層的攻堅克難、業務層的生態集結,還有「大模型評測」的戰場:所有大廠都想要把 GPT 比下去。
據不完全統計,8月以來,至少有 4 家本土大模型官宣在某些方面超越了 GPT。
科大訊飛表示星火大模型的代碼能力超過了 GPT 3.5;商湯說自己的新模型 internlm-123b 在51個評測集的30萬個問題上超過了 GPT 3.5;百川CEO王小川稱自家的模型微調后,在中文問答、摘要細分場景上的表現超越了 GPT 3.5;騰訊則更不客氣,副總裁蔣杰稱混元大模型中文能力全面超過 GPT-3.5。
如果沒有「在某個特定領域超過 GPT」的評測結果,似乎都不好意思加入這場大模型的混戰。
但讓一個模型成為某個「評測數據集」的頂級做題家,對于實際的效率提升,意義不大。
業內人士都知道有個投機取巧的訓練方法,是讓優質大模型在開源數據集上進行輸出,再用這些輸出的結果來微調小模型,直接抄大模型的作業。但伯克利學者研究表明,這些模仿模型只是看起來不錯,實際能力并沒有提升,在真實場景中的泛化能力較弱。
目前,OpenAl 的 GPT-3 擁有1750億個參數,本土大模型的規模一般在數百億到千億之間。
此外,脫離了具體使用場景的評測都是耍流氓。在toB辦公場景下,準確地提取數據,并給到穩定的輸出最重要。在toC陪伴場景中,模型的共情力、幽默感才是提供情緒價值的關鍵。各家發布的評測榜單,更像是 PR 行為,而非可用性評估。
百度智能云事業群總裁沈抖在接受采訪時說,市面上有非常多模型,但很多都會迅速消失。「現在很多模型之所以還存在,是因為很多人還不知道它的好壞。反正誰也試不了,誰也用不了,一測排名還挺靠前。但隨著模型的放開,優劣更容易評判了。」
已經到了逐漸放開的時刻。
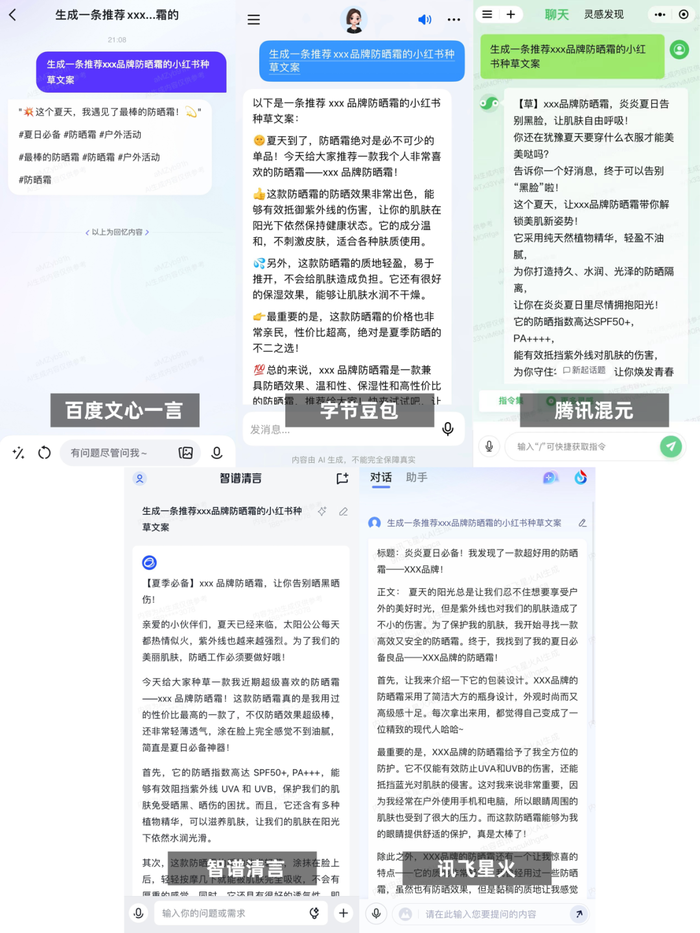
新莓daybreak 體驗了下目前 C 端可注冊的大模型產品。在生成「小紅書種草文案」這個任務上,幾款產品的表現均達到了「文通字順」,甚至「有點好用」。文心一言擅長加tag引流,豆包的文案頗有親切感,混元的文案有點4A廣告公司的味道,智譜清言像是嚴謹的語文老師,訊飛星火則從場景切入。還是本土模型最懂本土社交平臺。
但在 toB,大模型的腳尖已經觸碰到了應用場景的泥濘。
各家廠商從不低調,騰訊、華為、商湯、百度都曾提到,自己的大模型解決方案已覆蓋了十余個、數十個行業場景。但實際上,企業真的用起來了嗎?
「讓大模型成為某一行業的助理,比如金融行業的大模型,還是太泛泛了,需要把行業和場景拆得更細。」Peter說,他是一名算法工程師,在某金融機構從事大模型應用的開發和探索。
他介紹,以銀行為例,有多個主營業務。光是資本市場業務,下面就有定向增發、股權投資、股權激勵、債轉股、可交換債券等十余個子業務。僅僅是股權激勵,相關法律法規就有數十篇。
「現在我們甚至不能讓大模型學習股權激勵的法律法規上做出可靠的回答。10個問題,能有5個回答正確就已經相當好了。」
模型要大,應用要垂
不可否認的是,在中文大模型基座能力尚弱的時候,上層應用就已經先跑起來了。
「理想化的場景是,大模型可以在最初的交流中識別提問者的意圖,然后再分給掌握細分領域知識的、不同的 AI Agents,后續讓各個 AI Agents 去處理,而不是做一個大而全的法律AI助手、金融AI助手。」
David 是某家初創公司的 AI 產品經理,開發了一款類似 Character.ai 的產品。他認為,作為開發者,流程規劃、系統穩定等等工程層面的努力,對于落地應用來說更重要。
Magi 創始人季逸超,在播客中也提到過類似的觀點:「AI 創業是 80% 的產品工程 + 20% 的底層技術。」
季逸超認為,大模型超過 65% 的應用場景,是信息的檢索、匯總、再生成,約 20% 的需求是流程自動化、決策輔助。
以信息的檢索生成為例,看似簡單,實則每個角落、每個細節都需要優化。數據是否能夠處理干凈、文本塊的切分是否完整、訓練時樣本和機器怎么分布、響應速度和成本怎么權衡,這其中涉及到大量的工作。如果每個環節的質量都只有 60-70 分,那么串聯起來,最終可用性一定不理想。
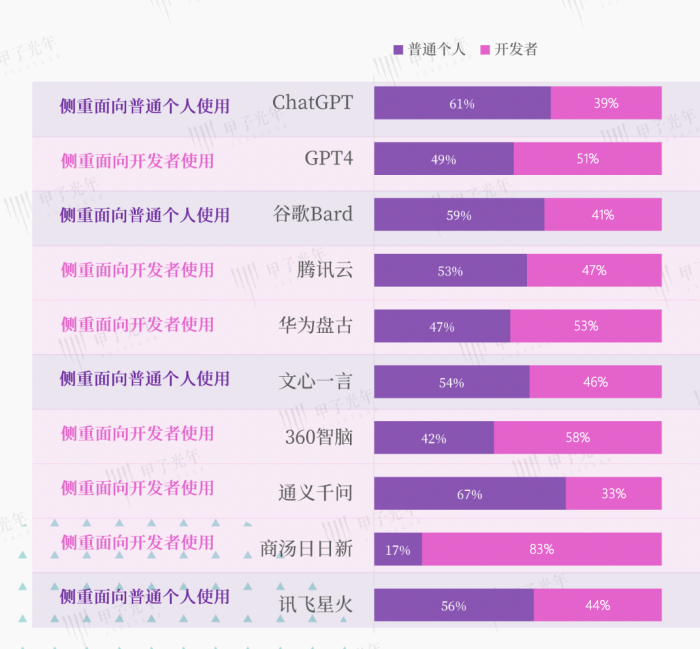
甲子光年對國內外熱度較高的 10 款大模型進行了客群分析,國外的大模型廠商,主要還是側重普通C端用戶使用,商業模式是收取訂閱費。而國內的大模型似乎都打定主意,做平臺、做生態,然后從 B 端客戶那里掙錢,商業模式包括按量計費的 API 調用,以及更加深入的解決方案服務、模型定制開發。
然而無論 toB 還是 toC,商業模式也許會有不同,讓用戶買單的關鍵還是基礎模型的能力。
畢竟,上層應用的能力,還是由底層模型決定的。基礎模型擁有的能力,上層應用不一定能夠發揮出來;但基礎模型沒有的能力,上層應用一定做不到。
Peter 坦陳,他們測試了一圈本土大模型,在真實場景下,表現都還「差點意思」。而對于行業模型微調,他們「想都不敢想」,因為「一次至少要 500 萬起」,效果卻尚未可知。
「所以現階段一定會有垂直應用,但不太可能有垂直模型。」Peter 總結道。
另一個國內應用開發者需要考慮的關鍵是合規。有兩項法規提供了具體指導:1月10日開始施行的《互聯網信息服務深度合成管理規定》,以及8月15日開始施行的《生成式人工智能服務管理暫行辦法》。
目前,AI 產品上線前需要通過算法備案和安全評估,業內稱之為「雙新評估」。可以說,能夠更快、更及時地做到合規,也是產品競爭力的一部分。
細心的用戶不難發現,目前國內 C 端可用的大模型對話產品界面,幾乎都有免責聲明和水印標記。前者提示 AI 生成的內容不一定保證真實,后者則是確保信息傳播時的可追溯性。
國產大模型只是剛剛從實驗室走向市場,開始面向真實用戶。此時就拿出商業世界的價值衡量標準,對它們發出極度務實的三連問,「能否真正提升工作效率、能否有效降低成本、能否優化用戶體驗」,未免顯得有些嚴苛。但這恰恰是企業用戶的真正關切,也是大模型在商業應用中的核心價值。