
文|適道
1. Google:Phenaki &Imagen Video
2. Meta:Make-A-Video
3. 百度:VidPress
4. 下一個明日之星?
沒有人懷疑,新時代已經到來。作為新時代“發電廠”,大模型正在改造著各行各業。
在AIGC領域,背靠大模型,以ChatGPT為代表的AI聊天機器人,以Midjourney為代表的AI圖片生成工具,掀起了第四次AI浪潮。
但這或許只是可口的前菜?
一方面,比起圖文,視頻是更強的商業化載體;另一方面,有了5G技術高帶寬、低時延的加持,視頻領域的技術革命近在眼前。
那么,下一個大模型的爆發點會在何處?是在視聽行業嗎?
從需求來看,AI生成時代之前,視頻生成的智能化主要用于后期剪輯;AI生成時代當下,接入大模型,成本和難度更大的素材采集可以輕松完成,而這剛好能夠滿足行業對“降本增效”的需求。
但從可實現性來看,根據易觀《AIGC產業研究報告2023——視頻生成篇》,生成視頻商業化落地的挑戰主要集中在產品易用性挑戰、穩定可控挑戰,以及合規應用挑戰。其中,“產品易用性”指視頻生產的速度、交互體驗等;“穩定可控”指可生成視頻的時長、分辨率,以及處理速度,對復雜場景的理解等。
總的來說,生成視頻的質量、互動的準度極大影響著其商業化落地。
那么現在的視頻生成技術走到了哪一步呢,不妨先展開看看相關領域的進展。
一篇來自Boxmining的文章給出了部分答案(作者Steve Gates),文章介紹了包括Phenaki 、Imagen Video、Make-A-Video在內的幾款AI視頻生成模型,并指出了AIGC領域的下一個爆點。以下是適道的翻譯簡寫。為方便大家絲滑閱讀,適道對原文結構進行了微調,并補充了文中提及的案例。
隨著大模型不斷發展,人們急切期待AI繪畫和ChatGPT后的下一個突破點。
在通信領域,5G技術的高帶寬、低時延,為視頻傳輸提供了強有力的保障,這會引發一場圍繞8K視頻、VR和AR的視頻技術革命。
綜上所述,技術法則預示著視頻領域的技術革命指日可待。隨著AI和5G技術的發展,視頻行業將迎來新一輪的創新發展浪潮。
1. Google:Phenaki &Imagen Video
在現象級產品ChatGPT大放異彩之時,Google的文生視頻(Text to Video,T2V)模型Phenaki的表現也相當炸裂。
Phenaki不受固定幀數、時長、分辨率的限制。它不僅比以前的模型更長、更復雜,分辨率更高,還能理解不同的藝術風格和3D結構。
僅根據單個提示詞,Phenaki就能生成一個能講故事的視頻(Story-Telling Video)。
當你想做一段泰迪熊動畫時,只需輸入:
A teddy bear diving in the ocean(一只泰迪熊潛入海中)
A teddy bear emerges from the water(一只泰迪熊從水中出現)
A teddy bear walks on the beach(一只泰迪熊走在沙灘上)
Camera zooms out to the teddy bear in the campfire by the beach(相機逐漸拉遠至沙灘邊篝火旁的泰迪熊)
幾分鐘后,你會獲得如下視頻:

怎么樣?質感相當不錯吧。

同時期,Google還推出了另一款基于擴散模型的Imagen Video,同樣擁有高分辨率,也可以理解不同藝術風格。不過,Imagen Video生成的視頻時長相比Phenaki來說更短。

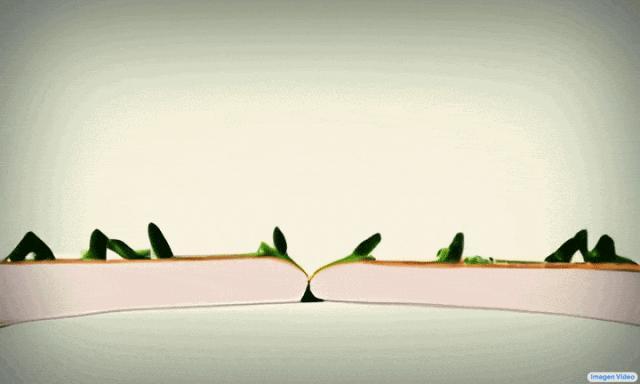
2. Meta:Make-A-Video
Meta也加入了這場視頻生成的卷王之戰中,并在2022年9月推出了Make-A-Video,時間比Google推出Phenaki &Imagen Video剛好早了一周。
根據Meta官網介紹,和上述的文生視頻T2V模型不同,Make-A-Video是建立在文本生成圖像(Text to Image,T2I)模型上的升級版本。
也就是說,雖然Make-A-Video生成的是視頻,但它沒有用成對的文本+視頻數據訓練,而是和文本生成圖像(Text to Image,T2I)模型一樣,靠文本+圖像的數據對進行訓練,這一方面是考慮到當前互聯網中的文本+視頻的數據集過少,另一方面是,可以對已經相對成熟的T2I模型進行重復使用。
那么,我們來看看Make-A-Video能做出哪些好玩的視頻?
1、將靜止圖像轉換成視頻

2、根據前后兩張圖片創建一個視頻

3、基于原始視頻生成新視頻

4、根據輸入的文字提示,生成符合語義的短視頻。
例如,輸入“喝水的馬”

輸入“機器人在時代廣場跳舞”

3. 百度:VidPress
到了國內,百度也將文心大模型的能力運用在智能視頻合成平臺VidPress中。
VidPress可以快速完成文字腳本、視頻內容搜索、素材處理、音視頻對齊、剪輯等一連串“騷操作”。
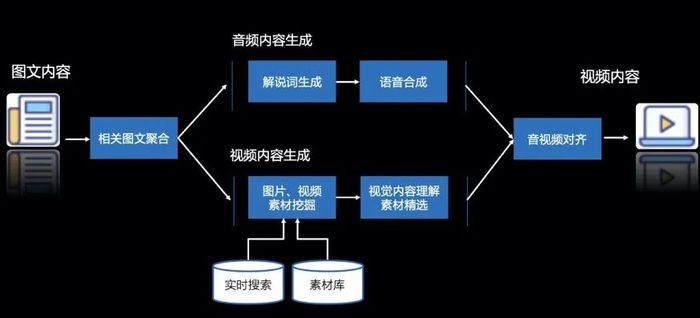
VidPress內容生產的三個環節
早在2021年1月,百度研究院就發布了一條由AI自主剪輯的視頻《2021年十大科技趨勢預測》,該視頻的技術支撐就是VidPress。
當下,一方面,文娛、教育、傳媒等諸多領域對AI生成視頻具有強烈市場需求;另一方面,AI生成內容產品存在變現困難等商業化瓶頸。而在2022年,一批高質量文生圖模型,如DALL E、Imagen和Stable Diffusion涌現,這將助力AI生成內容產業突破變現難等商業化瓶頸。
4. 下一個明日之星?
在大模型技術領域,兩類公司值得關注。
1、擁有數據基礎和應用場景的公司
以Netflix、Disney為代表的大型行業玩家為代表,這些公司積攢了數十億條會員評價,且熟知觀眾的習慣和需求。
事實上,Netflix已經使用AI來替代標準內容的制作,例如從影片中抽取符合用戶觀影偏好的畫面,生成電影縮略圖。
另外,今年1月31日,Netflix還發布了一支AIGC動畫短片《犬與少年(Dog and Boy)》。其中動畫場景的繪制工作就是由AI完成的。

2、科技巨頭核心研發團隊創建的初創公司
以OpenAI、DeepMind和Meta為代表,這些公司在該領域有著重大影響力。它們也憑借深厚的技術背景和創新精神,開發出了一系列領先的大模型技術。
有趣的是,這些公司原本的研究人員也跳了出來,強強聯手,成立新公司。
例如,前段時間,由DeepMind和Meta的前研究人員共同創立的Mistral AI,成為了資本的新“寵兒”。Mistral AI僅成立了四個星期,就獲得了一輪高達1.13億美元的種子資金。據外媒Techcrunch報道,這是歐洲生成式AI公司有史以來獲得的最大的種子輪融資。
結論
從ChatGPT到AIGC,再到如今的視頻生成模型,AI發展的速度之快令人驚嘆。
目前,在視頻生成領域,科技巨頭們正在爭先搶占領先地位。
不過,無論誰來搶占,如何搶占,他們的目標都是創造出更加真實、高質量的視頻。而這些技術不僅能為消費者帶來更深度的娛樂體驗,也將為媒體、教育、廣告等行業帶來巨大影響。
然而,這些正在更新的大模型技術也帶來了一些新的挑戰,如隱私問題、數據保護以及內容濫用問題。這需要我們在繼續推動技術進步的同時,積極應對這些挑戰,如制定相適應的規范和法規,以確保技術的健康發展。
無論如何,對于大模型技術的未來,我們有理由保持樂觀。隨著技術的不斷進步,我們期待在不久的將來看到更多的創新和突破。